Guides
How to Scrape Redfin: Python Guide to Property Data
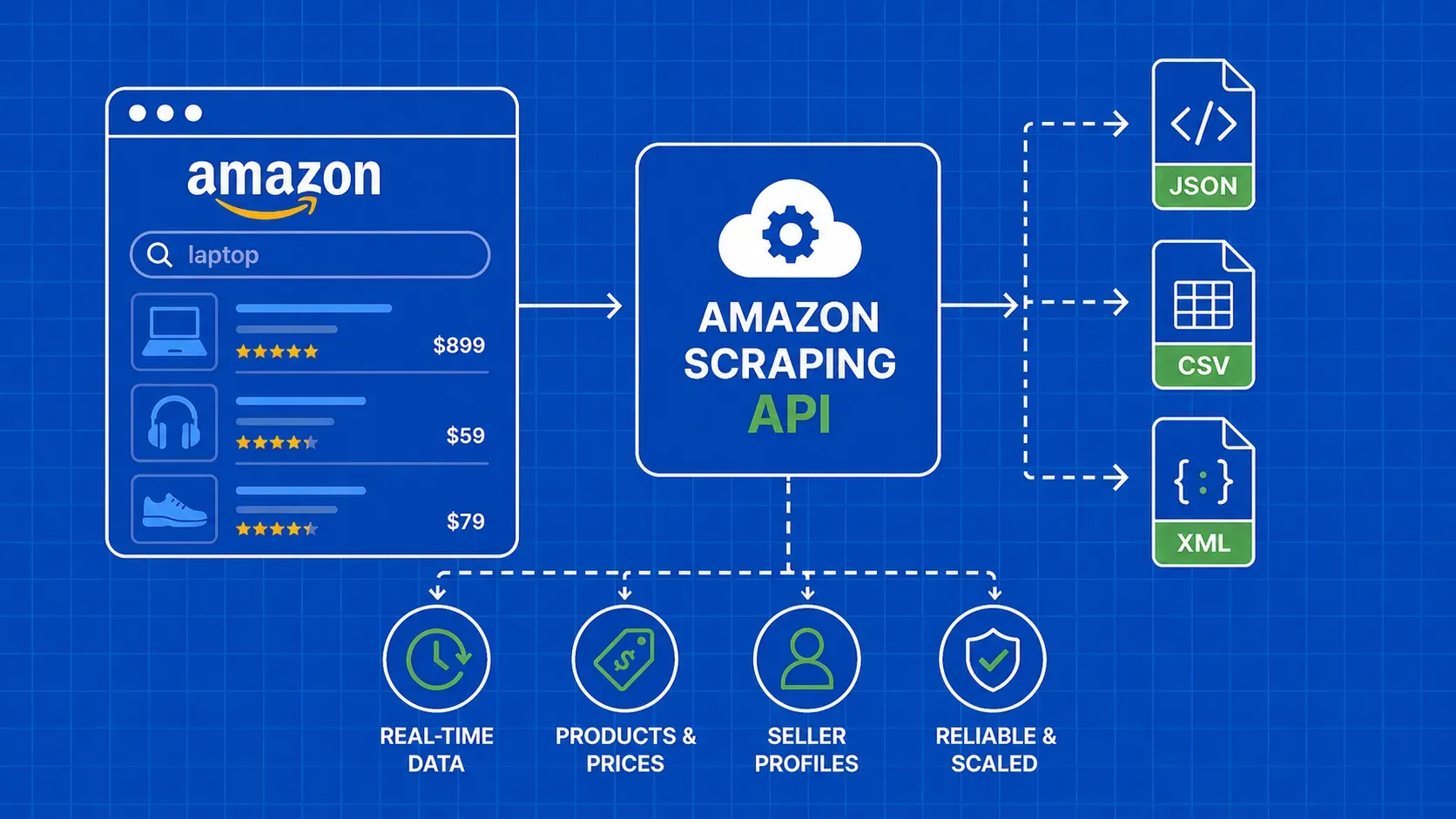
TL;DR: Redfin exposes hidden API endpoints that return structured JSON for property listings, making it possible to skip fragile HTML parsing entirely. This guide walks you through building a Python scraper that extracts rental and sale data, searches by location, monitors new listings via XML sitemaps, and exports clean results to CSV or JSON.
Suciu Dan11 min read
Apr 27, 2026