How to build a Web Scraper with Python and Selenium
Robert Sfichi on Jul 06 2021
Plenty of developers choose to make their own web scraper rather than using available products. If you ask most of them what programming language they prefer, you’ll most likely hear Python a whole bunch of times.
Python has become the crowd favorite because of its permissive syntax and the bounty of libraries that simplify the web scraping job. Today, we’re going to talk about one of those libraries.
This guide will cover how to start extracting data with Selenium and Python. We will build a Python script that will log in to a website, scrape some data, format it nicely, and store it in a CSV file.
If you want a more general overview of how Python can be used in web scraping, you should check out our ultimate guide to building a scraper with Python. Then, come back here so we can dive into even more details!
An overview of Selenium
Just as the official selenium website states, Selenium is a suite of tools for automating web browsers that was first introduced as a tool for cross-browser testing.
The API built by the Selenium team uses the WebDriver protocol to take control of a web browser, like Chrome or Firefox, and perform different tasks, like:
- Filling forms
- Scrolling
- Taking screenshots
- Clicking buttons
Now you might be wondering how all this translates into web scraping. It’s simple, really.
Data extraction can be a real pain in the neck sometimes. Websites are being built as Single Page Applications nowadays even when there’s no need for that. They’re popping CAPTCHAs more frequently than needed and even blocking regular users’ IPs.
In short, bot detection is a very frustrating feature that feels like a bug.
Selenium can help in these cases by understanding and executing Javascript code and automating many tedious processes of web scraping, like scrolling through the page, grabbing HTML elements, or exporting fetched data.
Installation
To show the real power of Selenium and Python, we are going to scrape some information off the /r/learnprogramming subreddit. Besides scraping data, I’ll also show you how signing in can be implemented. Now that we have an understanding of the primary tool and the website we are going to use, let’s see what other requisites we need to have installed:
1. Python. We will be using Python 3.0. However, feel free to use Python 2.0 by making slight adjustments. You can download and install it from here.
2. Selenium package. You can install the Selenium package using the following command:
pip3 install selenium
3. Pandas package. It will be used for extracting and storing scraped data in a .csv file. Please run the following command to install it on your device.
pip3 install pandas
4. BeautifulSoup package. Used for parsing HTML and XML documents. Just run this line:
pip3 install beautifulsoup
5. Google Chrome. Check this link to find more about how to download and install it.
6. Chrome driver. It will help us configure the web driver for Selenium. Please follow this link to download and install the latest version of chromedriver. Don’t forget to save the path you installed it to.
Starting the browser
Let’s get things started. Create a new scraper.py file and import the Selenium package by copying the following line:
from selenium import webdriver
We will now create a new instance of Google Chrome by writing:
driver = webdriver.Chrome(LOCATION)
Replace LOCATION with the path where the chrome driver can be found on your computer. Please check the Selenium docs to find the most accurate PATH for the web driver, based on the operating system you are using.
The final step is accessing the website we’re looking to scrape data from. In our case, this is https://www.reddit.com/r/learnprogramming/top/?t=month. Copy the following line in the newly created python file:
driver.get("https://www.reddit.com/r/learnprogramming/top/?t=month")By running the following command in a terminal window:
python3 scraper.py
We should now have a new instance of Google Chrome open that specifies ‘Chrome is being controlled by automated test software’ at the top of our page.
Locating specific data
As you probably already figured out, we will scrape the /r/learnprogramming subreddit in this tutorial. We will save the posts’ title, author, number of upvotes and store them in a new .csv file. Let’s see where they are situated on the HTML page and how we can extract them.
After Google Chrome finally loaded the page, let’s right-click on any post and hit ‘Inspect.’ We can find the post’s HTML container under the _1oQyIsiPHYt6nx7VOmd1sz class name.
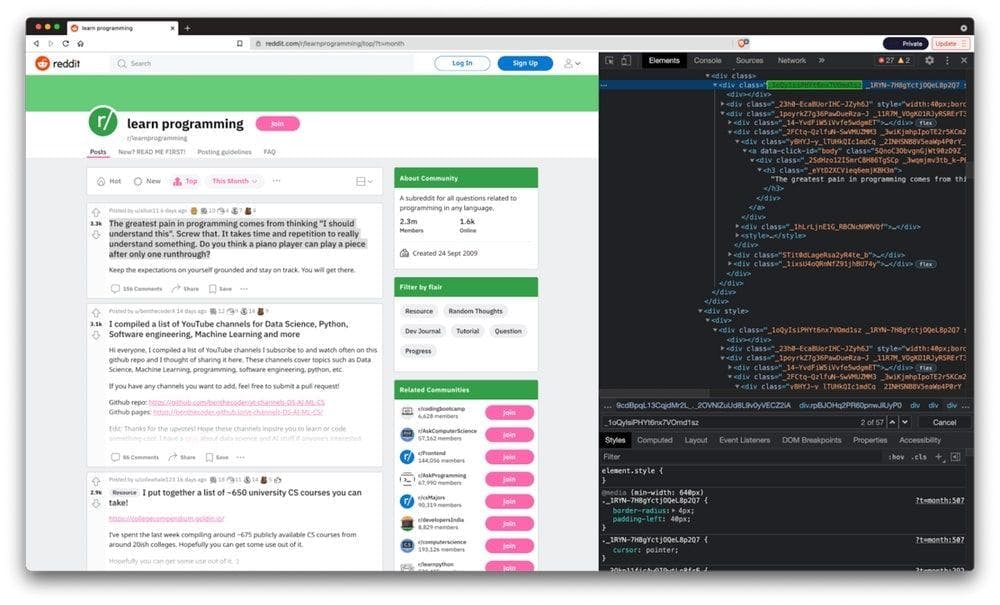
You can also run Google Chrome without a graphical user interface and log the page’s HTML content by adding a couple of lines of code. We will set the headless option to true for the chrome driver (to remove the graphical interface) and a window size of 1080 pixels (to get the correct HTML code for our use case).
The last two lines of code exit Chrome right after finishing logging the page’s HTML.
The new scraper.py file will look like this:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome("./chromedriver")
driver.get("https://www.reddit.com/r/learnprogramming/top/?t=month")
print(driver.page_source)
driver.quit()
WebElement
A WebElement is a Selenium object that represents an HTML element. As you will see in the following tutorial, we can perform many actions on these elements. Some of them are:
- Clicking on it by using the .click() method
- Providing text to a specific input element by calling the .send_keys() method
- Reading the text of an element by using element.text
- Checking if an element is displayed on the page by calling .is_displayed() on it
An example of Selenium in action
Now that we have our project set up, we can finally get to scraping.
Logging in
We are going to showcase the power of Selenium by logging in to our Reddit account and scraping the previously presented data. Let’s start by making Selenium click on the login button at the top of the page. After inspecting the page’s HTML, we can see that the login button’s class name is _2tU8R9NTqhvBrhoNAXWWcP.
login_button = driver.find_element_by_class_name('_2tU8R9NTqhvBrhoNAXWWcP')
login_button.click()
This will open up the login modal where we can see the user and password inputs we have to fill up. Let’s continue with the following lines:
driver.switch_to_frame(driver.find_element_by_class_name('_25r3t_lrPF3M6zD2YkWvZU'))
driver.find_element_by_id("loginUsername").send_keys('USERNAME')
driver.find_element_by_id("loginPassword").send_keys('PASSWORD')
driver.find_element_by_xpath("//button[@type='submit']").click()If we inspect the modal element, we can see that its container is an iframe. This is why we have to switch to frame in the first part of the code, as selecting the inputs without it will result in an error.
Next, we get the input elements and provide them with the proper credentials before hitting the submit button. This will bring us back to the /r/learnprogramming page, but now we are logged in and ready to upvote!
Taking a screenshot
Taking a screenshot using Selenium and Python is pretty easy. All you have to do is write the following command in the scraper.py file after declaring the web driver.
driver.save_screenshot('screenshot.png')It’s useful to know that you can set the Google Chrome window size by adding the following lines of code:
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--window-size=1920,1080")
This is how the screenshot will look in our case:
Extracting data
As we have previously stated, we need to get the posts’ title, author, and number of upvotes. Let’s start by importing BeautifulSoup and Pandas packages and creating three empty arrays for every type of information we need.
from bs4 import BeautifulSoup
import pandas as pd
titles = []
upvotes=[]
authors = []
We are going to use BeautifulSoup to parse the HTML document by writing the following lines:
content = driver.page_source
soup = BeautifulSoup(content, features="html.parser")
After successfully inspecting the HTML document and choosing the right selectors, we are now going to fetch the titles, upvotes, and authors and assign them to the right array:
for element in soup.findAll('div', attrs={'class': '_1oQyIsiPHYt6nx7VOmd1sz'}):
title = element.find('h3', attrs={'class': '_eYtD2XCVieq6emjKBH3m'})
upvote = element.find('div', attrs={'class': '_3a2ZHWaih05DgAOtvu6cIo'})
author = element.find('a', attrs={'class': '_23wugcdiaj44hdfugIAlnX'})
titles.append(title.text)
upvotes.append(upvote.text)
authors.append(author.text)Finally, we will store the information in a CSV file using the Pandas package we imported earlier.
df = pd.DataFrame({'Post title': titles, 'Author': authors, 'Number of upvotes': upvotes})
df.to_csv('posts.csv', index=False, encoding='utf-8')That’s it! Let’s take a look at the exported file:
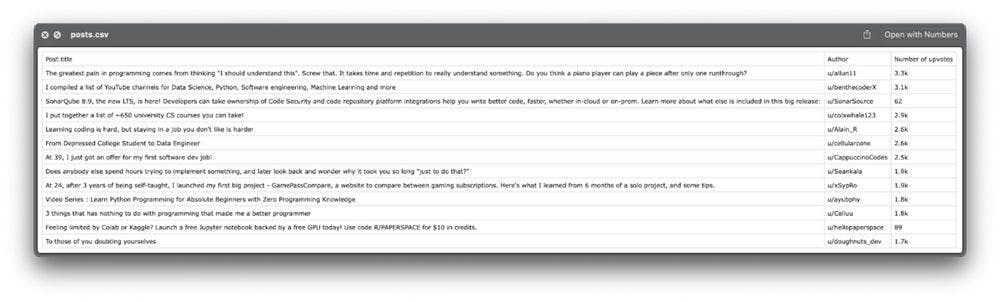
It seems to have all the information we need.
Bonus tip: Sometimes, we need more data than the website provides on the first load. Most of the time, the fetching data action fires when the user scrolls down. If you need to scroll down to get more data, you can use the .execute_script() method like this:
scrollDown = "window.scrollBy(0,2000);"
driver.execute_script(scrollDown)
Closing thoughts
I hope you enjoyed creating the web scraper just as much as I did. Programming isn’t always fun, but building little scripts like this reminds me of when I was just starting out, and it makes the process much more entertaining.
Still, the script we managed to build in this tutorial can’t do a lot of hard work. It lacks a couple of essential features that make web scraping feel flawless. Connecting using mobile or residential proxies and solving CAPTCHAs are just a couple of them.
If you’re looking for a more professional way to extract data, take a look at what WebScrapingAPI can do and see for yourself if there’s a match. There’s a free package, so the only investment is 30 minutes of your attention.
Thank you for taking the time to read this. Happy scraping!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Learn how to scrape dynamic JavaScript-rendered websites using Scrapy and Splash. From installation to writing a spider, handling pagination, and managing Splash responses, this comprehensive guide offers step-by-step instructions for beginners and experts alike.


Learn what’s the best browser to bypass Cloudflare detection systems while web scraping with Selenium.
