Web Scraping with Puppeteer Advanced Node.JS
Gabriel Cioci on Jul 28 2021
Rather than using commercial tools, many developers prefer to create their own web scrapers. While available products have more fleshed out features, we can’t deny the results these bots can bring or the fun of making your own.
In the following article, you’ll find out the steps you have to take to build your own web scraper using Node.js and Puppeteer. We’ll code an app that loads a website, snaps a screenshot, log in to the website using a headless browser and scrape some data across multiple pages. Your app will grow in complexity as you progress.
An overview of Web Scraping with Puppeteer
Google designed Puppeteer to provide a simple yet powerful interface in Node.js for automating tests and various tasks using the Chromium browser engine. It runs headless by default, but it can be configured to run full Chrome or Chromium.
The API build by the Puppeteer team uses the DevTools Protocol to take control of a web browser, like Chrome, and perform different tasks, like:
- Snap screenshots and generate PDFs of pages
- Automate form submission
- UI testing (clicking buttons, keyboard input, etc.)
- Scrape a SPA and generate pre-rendered content (Server-Side Rendering)
Most actions that you can do manually in the browser can also be done using Puppeteer. Furthermore, they can be automated so you can save more time and focus on other matters.
Puppeteer was also built to be developer-friendly. People familiar with other popular testing frameworks, such as Mocha, will feel right at home with Puppeteer and find an active community offering support for Puppeteer. This led to a massive growth in popularity amongst the developers.
Of course, Puppeteer isn’t suitable only for testing. After all, if it can do anything a standard browser can do, then it can be extremely useful for web scrapers. Namely, it can help with executing javascript code so that the scraper can reach the page’s HTML and imitating normal user behavior by scrolling through the page or clicking on random sections.
These much-needed functionalities make headless browsers a core component for any commercial data extraction tool and all but the most simple homemade web scrapers.
Prerequisites
First and foremost, make sure you have up-to-date versions of Node.js and Puppeteer installed on your machine. If that isn’t the case, you can follow the steps below to install all prerequisites.
You can download and install Node.js from here. Node’s default package manager npm comes preinstalled with Node.js.
To install the Puppeteer library, you can run the following command in your project root directory:
npm install puppeteer
# or "yarn add puppeteer"
Note that when you install Puppeteer, it also downloads the latest version of Chromium that is guaranteed to work with the API.
Puppeteer in action
There are many different things you can do with the library. Since our main focus is web scraping, we’ll talk about the use cases that are the most likely to interest you if you want to extract web data.
Taking a screenshot
Let’s start with a basic example. We’ll write a script that will snap a screenshot of a website of our choice.
Keep in mind that Puppeteer is a promise-based library (it performs asynchronous calls to the headless Chrome instance under the hood). So let’s keep the code clean by using async/await.
First, create a new file called index.js in your project root directory.
Inside that file, we need to define an asynchronous function and wrap it around all the Puppeteer code.
const puppeteer = require('puppeteer')
async function snapScreenshot() {
try {
const URL = 'https://old.reddit.com/'
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto(URL)
await page.screenshot({ path: 'screenshot.png' })
await browser.close()
} catch (error) {
console.error(error)
}
}
snapScreenshot()First, an instance of the browser is started using the puppeteer.launch() command. Then, we create a new page using the browser instance. For navigating to the desired website, we can use the goto() method, passing the URL as a parameter. To snap a screenshot, we’ll use the screenshot() method. We also need to pass the location where the image will be saved.
Note that Puppeteer sets an initial page size to 800×600px, which defines the screenshot size. You can customize the page size using the setViewport() method.
Don’t forget to close the browser instance. Then all you have to do is run node index.js in the terminal.
It really is that simple! You should now see a new file called screenshot.png in your project folder.
Submitting a form
If, for some reason, the website you want to scrape doesn’t show the content unless you’re logged in, you can automate the login process with Puppeteer.
Firstly we need to inspect the website that we’re scraping and find the login fields. We can do that by right-clicking on the element and choosing the Inspect option.
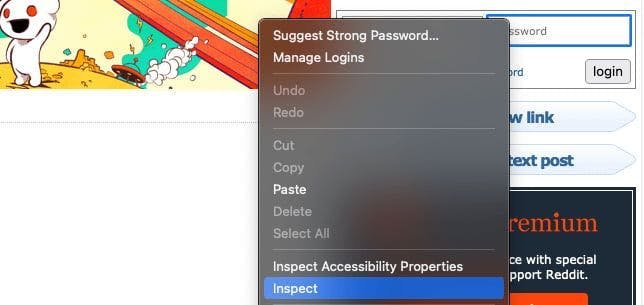
In my case, the inputs are inside a form with the class login-form. We can enter the login credentials using the type() method.
Also, if you want to make sure that it does the correct actions, you can add the headless parameter and set it to false when you launch the Puppeteer instance. You’ll then see how Puppeteer does the entire process for you.
const puppeteer = require('puppeteer')
async function login() {
try {
const URL = 'https://old.reddit.com/'
const browser = await puppeteer.launch({headless: false})
const page = await browser.newPage()
await page.goto(URL)
await page.type('.login-form input[name="user"]', 'EMAIL@gmail.com')
await page.type('.login-form input[name="passwd"]', 'PASSWORD')
await Promise.all([
page.click('.login-form .submit button'),
page.waitForNavigation(),
]);
await browser.close()
} catch (error) {
console.error(error)
}
}
login()To simulate a mouse click we can use the click() method. After we click the login button, we should wait for the page to load. We can do that with the waitForNavigation() method.
If we entered the correct credentials, we should be logged in now!
Scrape multiple pages
I will use the /r/learnprogramming subreddit for this article. So we want to navigate to the website, grab the title and URL for every post. We’ll use the evaluate() method for that.
The code should look like this:
const puppeteer = require('puppeteer')
async function tutorial() {
try {
const URL = 'https://old.reddit.com/r/learnprogramming/'
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto(URL)
let data = await page.evaluate(() => {
let results = []
let items = document.querySelectorAll('.thing')
items.forEach((item) => {
results.push({
url: item.getAttribute('data-url'),
title: item.querySelector('.title').innerText,
})
})
return results
})
console.log(data)
await browser.close()
} catch (error) {
console.error(error)
}
}
tutorial()Using the Inspect method presented earlier, we can grab all the posts by targeting the .thing selector. We iterate through them, and for each one, we get the URL and the title and push them into an array.
After the entire process is completed, you can see the result in your console.
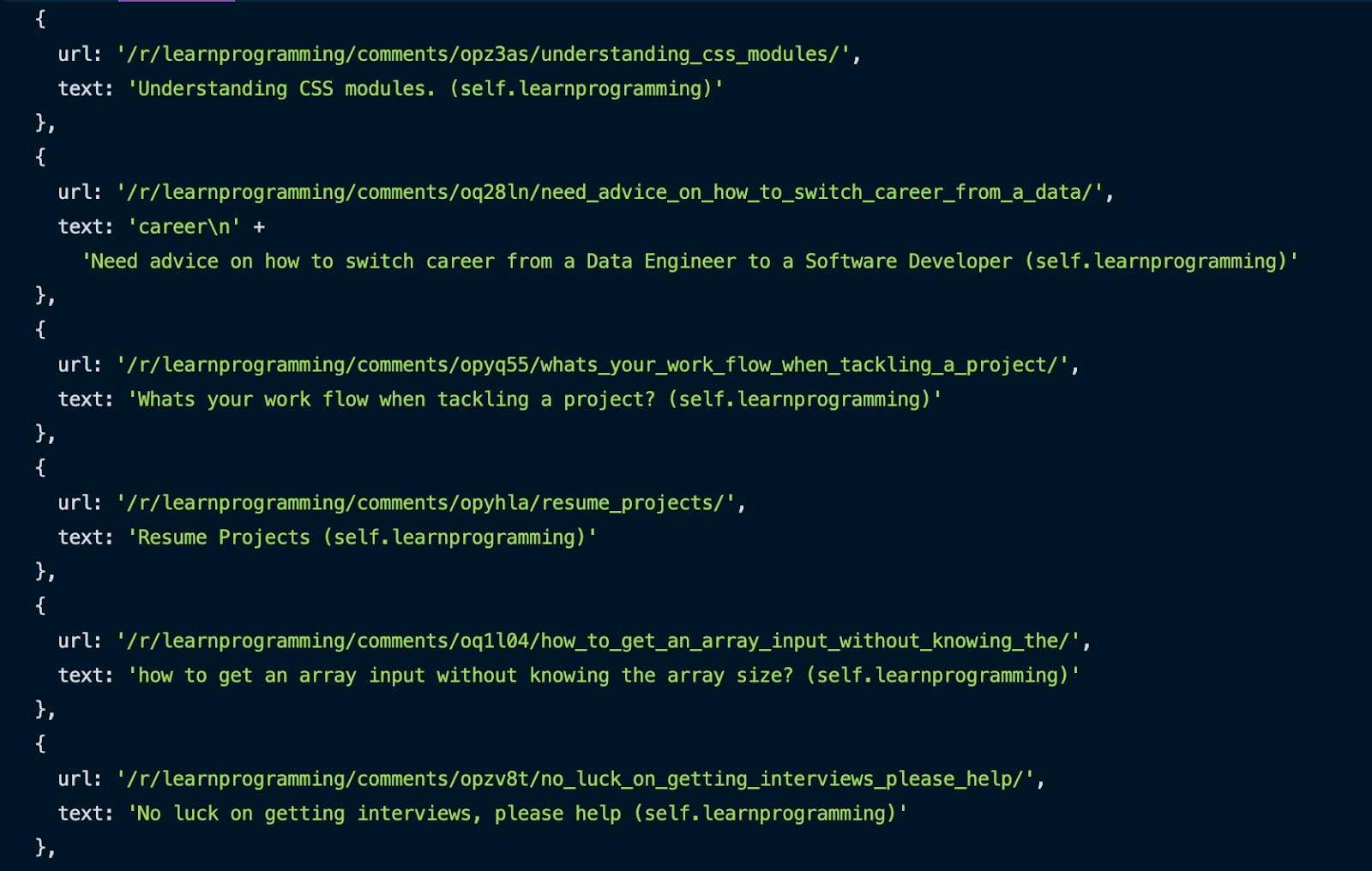
Great, we scraped the first page. But how do we scrape multiple pages of this subreddit?
It’s simpler than you think. Here’s the code:
const puppeteer = require('puppeteer')
async function tutorial() {
try {
const URL = 'https://old.reddit.com/r/learnprogramming/'
const browser = await puppeteer.launch({headless: false})
const page = await browser.newPage()
await page.goto(URL)
let pagesToScrape = 5;
let currentPage = 1;
let data = []
while (currentPage <= pagesToScrape) {
let newResults = await page.evaluate(() => {
let results = []
let items = document.querySelectorAll('.thing')
items.forEach((item) => {
results.push({
url: item.getAttribute('data-url'),
text: item.querySelector('.title').innerText,
})
})
return results
})
data = data.concat(newResults)
if (currentPage < pagesToScrape) {
await page.click('.next-button a')
await page.waitForSelector('.thing')
await page.waitForSelector('.next-button a')
}
currentPage++;
}
console.log(data)
await browser.close()
} catch (error) {
console.error(error)
}
}
tutorial()We need a variable to know how many pages we want to scrape and another variable for the current page. While the current page is less than or equal to the number of pages that we want to scrape, we grab the URL and title for each post on the page. After each page is harvested, we concatenate the new results with the ones already scraped.
Then we click the next page button and repeat the scraping process until we reach the desired number of extracted pages. We also need to increment the current page after each page.
An even easier option
Congratulations! You have successfully built your own web scraper with Puppeteer. I hope you enjoyed the tutorial!
Even so, the script we created in this guide cannot do a lot of hard work. It is missing a few key aspects that make web scraping feel flawless. Using mobile or residential proxies and solving CAPTCHAs are just a few of the missing functionalities.
If you're looking for a more professional way to extract data, take a look at what WebScrapingAPI can accomplish and see if it's a good fit. There's a free package, so all you have to invest in is 30 minutes of your time.
Happy web scraping!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Learn what’s the best browser to bypass Cloudflare detection systems while web scraping with Selenium.


Discover 3 ways on how to download files with Puppeteer and build a web scraper that does exactly that.

Learn how to use Playwright for web scraping and automation with our comprehensive guide. From basic setup to advanced techniques, this guide covers it all.
