Rotating Proxies: Everything You Need To Know
Raluca Penciuc on Jan 08 2023

When you started learning the basics of web scraping, did you have an “oh damn, I’ll need proxies for this” moment? Well, prepare to have that kind of epiphany all over again because rotating proxies are the next level in web scraping functionality.
Don’t believe me? Let’s look at the benefits proxies bring if you don’t rotate them and then at the extra advantages you get through rotation. Here’s what non-rotating IPs bring:
- You can retry scraping a page/website after the initial IP is blocked.
- You can manually switch addresses to get past websites that use geolocation to restrict content.
- You don’t give away your actual location.
- By adding a request delay, you can extract data from websites with anti-scraping countermeasures.
Those are definitely good things to have, but let’s see what happens when you add a new spin (pun intended):
- The scraper continually sends requests until it manages to get the information you need.
- You can easily access geo-restricted content from any country where you have a proxy.
- Websites don’t even know that bots are visiting them.
- You can get data from any website without having to slow down requests.
That’s just a quick rundown of the differences, but it’s pretty impressive, no? So let’s dive in and learn how these benefits come to be!
What are rotating proxies?
By rotating proxies, we mean the process of automatically switching from one IP to another with each request sent. In theory, this can be done manually, but it would mean that you couldn’t queue a list of URLs for scraping. Instead, you’d have to assign a proxy, send a request, assign another proxy, send another request, and so on. I hope you see how inefficient that would be.
For automatic proxy rotation, you’ll need a new intermediary, a proxy to your proxy, if you will. This new middle-man is a server that has access to your whole proxy pool. So instead of you searching through the IP list, the server does that for you. All you have to do is give it the command.
Here’s a play-by-play of the scraping process with a program that rotates proxies:
- The user sends a request to the proxy management server.
- The server picks a proxy at random (unless otherwise specified) and sends the request to it.
- The proxy then sends the request to the final target, the webpage with data to extract.
- The response takes the same route back to the user.
These four steps are repeated until the user has all the information he or she wants. Every request goes through a new proxy, simulating the actions of many different users connecting to a website.
So, in essence, rotating proxies take no extra work on your part. That’s the beauty of it. It’s more automation for a tool that’s already meant to gather tonnes of information without effort from the user.
Of course, for IP rotation, you need a proxy pool first and foremost. However, since not all proxies are the same, you need to gather the right IPs, too. Here are the two leading contenders:
Datacenter vs. Residential
There are several ways to classify proxies. You can go by anonymity, access, or origin. That latter factor is the most important for web scraping projects. In that sense, proxies are generally either datacenter or residential. Let’s look at each.
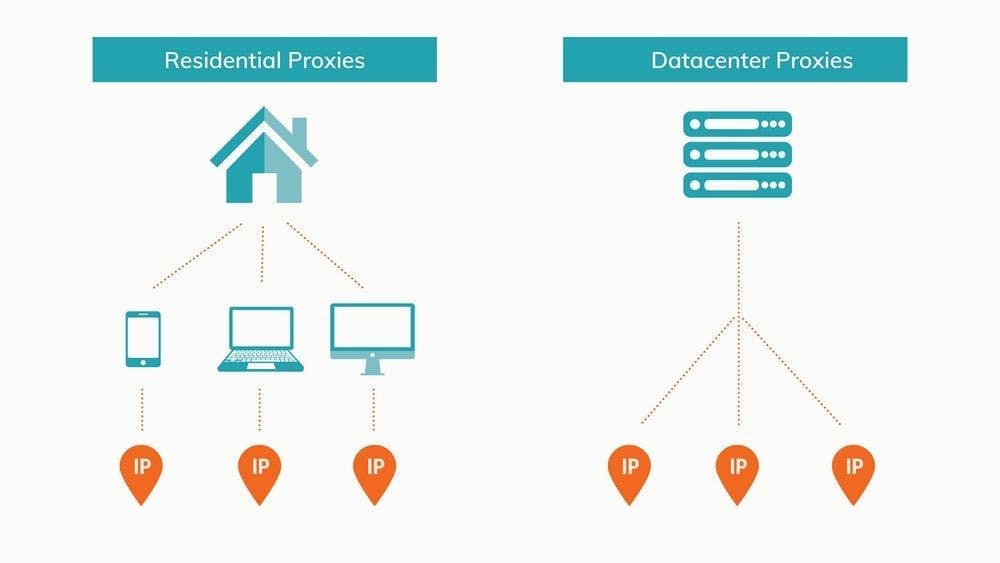
Rotating datacenter proxies
Data centers are named so because of their unrivaled capacity to store and share information online. The term “stored in the cloud” is just a more concise way of saying “stored in a data center, and you can access it as long as you have Internet.” The shorter version rolls off the tongue a lot better.
Data centers are essentially huge collections of interconnected servers with a colossal combined storage capacity and the infrastructure to keep them running. Datacenter proxies, as you may have guessed, are hosted by these structures. To get proxies, you have to create a virtual server, install an operating system on it, then install specialized software to set up IPs as proxies.
The key to efficient datacenter proxies is finding the right balance of servers and IPs. A server can hold multiple IPs, but each one creates more overhead. At some point, you'll get diminishing returns from the server and have to make a new one. Server and IP juggling is a lot of work, so most developers prefer to just rent or buy these proxies from specialized companies.
The IPs aren’t associated with an Internet Service Provider. Instead, you’re dealing with the data center owners or a third party that uses storage space to set up proxies and distribute them to customers.
They’re a popular choice for web scrapers because:
- They’re inexpensive compared to residential IPs due to the way they’re set up en masse;
- Their superior speed means that you can gather more data in less time;
- They’re very reliable thanks to the data centers’ solid infrastructure;
- It’s easy to buy or rent in bulk from the same server farm.
Of course, everything has its downsides. For datacenter proxies, those are:
- Their IPs are easier to spot by vigilant websites;
- All proxies from the same data center share a subnet identifier, making them more prone to blanket banning.
- It’s more challenging to build a proxy pool with IPs from every country as data centers are few in number.
By using rotating datacenter proxies, you can successfully access and scrape most websites. Since every new request comes from a different IP, it’s relatively difficult to track and block the scraper.
Advanced and popular websites are a different story. Amazon, Google, and other significant names face scrapers and other bots daily. As a result, it’s much more likely to be noticed. Moreover, datacenter proxies always run the risk of already being banned since all IPs from the same data center share a subnet.
What matters most is who you choose as your proxy service provider and how they manage their IPs. For example, WebScrapingAPI datacenter proxies are private and guarantee little to no blacklisting.
Rotating residential proxies
If data centers are the new and high-tech alternative, residential IPs are the tried and true option. Residential IPs are real devices connected to the web through an ISP. These proxies are virtually indistinguishable from normal users because, in a sense, they are just that.
Setting up a datacenter proxy pool takes some CS knowledge, money, and the right software. On the other hand, gathering residential IPs is a lot more complicated. First, you’d have to convince people to let you install specialized software on their device that gives you access from afar. Then, they’d have to always leave the machines on. Otherwise, the proxy would sometimes be unusable.
Due to the inconvenience and the needed degree of trust, it’s supremely easier for developers to rent residential proxies from dedicated service providers.
Compared to datacenter proxies, residential IPs have a few key advantages:
- Residential IPs are backed by ISPs and look like regular visitors while surfing the web, making the scraper harder to detect;
- Each IP is unique, so even if one proxy is identified and blocked, all others are still usable;
- It’s easier to prepare a proxy pool from a wide range of locations, assuring easier access to geo-restricted content.
Despite these substantial benefits which make residential proxies the best of the best in terms of effectiveness, they also have a few drawbacks:
- They generally have a higher cost;
- Due to location and the device’s Internet connection, request speed varies from IP to IP and are generally slower than datacenter proxies;
- You have to carefully choose a residential proxy provider, making sure that they offer a good number of IPs and that they have proxies in the countries you require for your project.
Residential proxies combined with an IP rotation system and a script that cycles request headers (especially user-agent) provide the best cover. With those, your web scraper can gather data without running into barriers, such as IP blocks or CAPTCHAs.
Due to their authenticity, residential proxies are often used for scraping more complex websites, like search engines, large eCommerce sites, or social media platforms. However, if you log in on these sites, turn proxy rotation off so that all requests come from the same IP. Otherwise, it will look like the same user is sending requests from all over the globe in a matter of seconds, proving that it’s a bot.
Why you should use rotating proxies for web scraping
Some websites tend to be popular targets for web scrapers. Google, Amazon, and Facebook come to mind. These platforms expect bots, so they implement methods to both slow down and stop them. With the increase in popularity that web scrapers are experiencing, these countermeasures are being used by more and more websites.
In this context, it’s becoming more and more vital that you rotate your IPs. Otherwise, you risk running into constant IP blocks, captchas, and your proxy pool slowly becomes ineffectual.
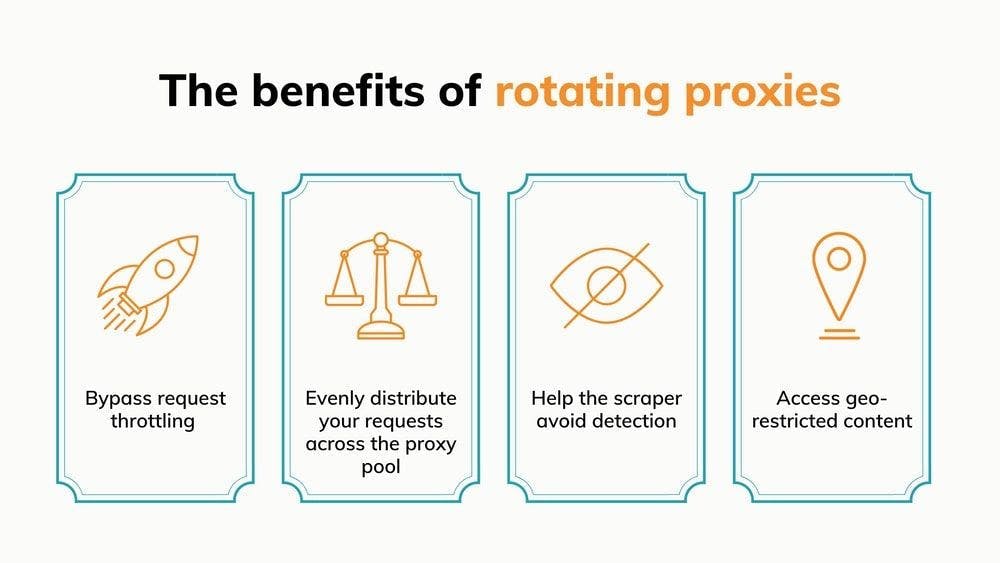
Bypass request throttling
Request throttling is a technique through which websites decrease the speed at which bots can navigate. Simply put, it limits the number of requests that a visitor can make in a specified amount of time.
Once the limit is reached, the bot is redirected to a CAPTCHA page. If your web scraping tool doesn’t have CAPTCHA solving capabilities or they fail to work, the IP can’t continue scraping on that website.
The key takeaway here is that websites monitor the number of requests sent from each IP. If your requests are sent from multiple addresses, the load is shared between them. Here’s an example:
If a website is set up so that after 10 requests, the 11th will trigger a CAPTCHA, that means you can scrape 10 pages before you have to stop and manually change the IP. If you’re collecting price intelligence, that might be a drop in the bucket compared to the total number of pages you want to scrape.
By rotating your proxies, you eliminate the need to intervene manually. You’ll be able to scrape ten times the number of proxies you have. Then, the only limit is the proxy pool’s size, each IP being used to its full potential.
The best part is that request throttling limits the number of visits over a set period. With a large enough proxy pool, the timer for the proxies you already used will expire before you have to call on them again, giving you virtually unlimited scraping capabilities.
Evenly distribute requests across the proxy pool
By the same logic as the previous point, proxy rotation ensures that you’re not overusing the same IPs while others sit idly. In the most basic terms, you’re using your resources as efficiently as possible. The result — you may get the same results with a smaller number of IPs.
Without proxy rotation, you’re using the same IP until it gets blocked while all other proxies are gathering dust. When one stops working, you go onto the next. This method makes proxies seem like a finite resource that’s used up to collect data. That’s not necessary.
With good location spread and data center/residential distribution, a decent proxy pool can go on indefinitely if you rotate IPs. All you need to make sure is that no one proxy stands out and risks getting blocked.
In the same vein, proxy rotation can exponentially speed up the scraping process. The key here is concurrent requests. Most web scraping APIs can send several requests simultaneously, the number depending on your chosen package.
Sending 50 requests at the same time towards the same website is bound to raise some red flags. In fact, it’s so far removed from normal user behavior that you’ll most likely be blocked immediately. You can probably guess where this is going. Rotating your proxies is a must, as it lets you push the scraper to its limits without getting blocked.
Help the scraper avoid detection
While on the subject of being blocked, one of the most significant advantages of rotating proxies is the anonymity it ensures. Let’s elaborate!
Websites are not too keen on being visited by bots. They may be trying to stop you from collecting data or just trying to ensure that no malicious program is trying to crash their servers. That’s why they implement several countermeasures to detect and block bots. Because web scrapers surf the Internet faster than regular users, they stand out. Think back to the example with 50 concurrent requests. According to ContentSquare’s 2020 Digital Experience Benchmark, the average user spends 62 seconds on a single page. The difference in behavior is plain to see.
With rotating proxies, you constantly swap between IPs and avoid sending numerous requests from a single address. The result — the website sees the traffic you generate as a group of separate visitors with no connection between them.
Access geo-restricted content
A proxy rotator shouldn’t just switch IPs at random. Sure, sometimes that’s enough, but a more advanced functionality you should look for is the option to rotate proxies from a specific region.
This feature is critical when you’re trying to collect information that pertains to a single region. Depending on the geographical source of a request, some websites may:
- Display data specific to the IP’s origin
- Restrict access because the request is coming from a blocked country
So, by rotating a diverse proxy pool, you can both mitigate the downsides while capitalizing on the benefits. Applied to the previous points, that means:
- Gain a better overview of foreign markets by obtaining data specific to several countries;
- Extract information that would otherwise be inaccessible due to certain countries being blocked from the website.
It’s important to stay vigilant and notice when websites customize their content based on the request’s origin. These sites have the potential to offer great insights into a country’s data. Still, if you don’t know you’re receiving custom information, you might end up with significant inaccuracies in your data.
How to use rotating proxies
Like web scrapers, you can build, manage and use a proxy rotator all on your own. For that, you’ll need programming knowledge (Python is ideal as it has many valuable frameworks and an active community), some general CS knowledge, a list of proxies, and a whole lot of patience.
The most basic form would be a script that receives a variable containing your proxy list and assigns random IPs for each request. For example, you could use the random.sample() function to pick one IP at complete random each time, but that means that the same proxy might be used several consecutive times. In that case, you could make it so that after an IP is used, it’s taken out of the proxy list, so it won’t be used again until all other addresses are used as well.
Here’s a short example in Python:
import random
import requests
proxy_pool = ["191.5.0.79:53281", "202.166.202.29:58794", "51.210.106.217:443", "5103.240.161.109:6666"]
URL = 'https://httpbin.org/get'
while len(proxy_pool) >0:
random_proxy_list = random.sample(proxy_pool, k=1)
random_proxy = {
'http': 'http://' + random_proxy_list[0],
}
response = requests.get(URL, proxies=random_proxy)
print(response.json())
proxy_pool.remove(random_proxy_list[0])
The code only cycles the proxy pool once and does it for a single URL, but it should illustrate the logic well. I grabbed the IPs from https://free-proxy-list.net/, by the way. Unsurprisingly, they didn’t work.
That’s kind of the problem with building your own rotator, in fact. You’ll still need good dedicated or at least shared IPs. Once you’re at the point of buying proxies, you might as well look for a solution that rotates the IPs for you as well. This way, you don’t spend extra time building it or extra money outsourcing it. Also, you get more goodies like:
- A quick option to rotate only IPs from a specific region;
- The chance to choose what kinds of proxies to cycle (datacenter or residential; regular or mobile; etc.)
- Setting up static IPs for when you’re scraping behind a login screen;
- Automatic retries with fresh IPs when a request fails.
Let’s take WebScrapingAPI as an example of how easy it is to scrape a page with rotating proxies. The following code is straight from the documentation, where there are many other snippets like it:
import requests
url = "https://api.webscrapingapi.com/v1"
params = {
"api_key":"XXXXXX",
"url":"https://httpbin.org/get",
"proxy_type":"datacenter",
"country":"us"
}
response = requests.request("GET", url, params=params)
print(response.text)
This is all the code you need to scrape an URL while using datacenter proxies from the US. Note that there’s no list of IPs to rotate or even a parameter for it. That’s because the API switches proxies by default. If you want to use the same IP for multiple sessions, just add a new parameter:
import requests
url = "https://api.webscrapingapi.com/v1"
params = {
"api_key":"XXXXXX",
"url":"https://httpbin.org/get",
"proxy_type":"datacenter",
"country":"us",
"session":"100"
}
response = requests.request("GET", url, params=params)
print(response.text)
Just use the same integer for the “session” parameter to use the same static IP for any URL.
The best rotating proxy providers
Now that you know how rotating proxies can optimize the web scraping process, the next step should be to choose a proxy provider that fits your needs and resources. I have compiled a list of my favorite ones based on several different factors: pricing, proxy locations, and the number of datacenter and residential proxies.
1. WebScrapingAPI

Let me ask you: what’s better than getting fast, efficient, and affordable proxies to connect to your web scraper?
The answer — getting a fast, efficient, and affordable web scraping API that does it all for you. I could go on and on about WebScrapingAPI’s data extraction functionalities, but let’s focus on IPs for now. The total proxy pool has over 100 million IPs spread around the globe.
Instead of measuring bandwidth usage, you get to choose a package with a certain number of API calls. Each API call means a scraped page, each through a different IP since, as I mentioned, proxy rotation is on by default.
There are five packages to choose from, including a free option that gives you 1,000 API calls each month (besides the free trial) to form your opinion on the product. The price starts at $20 for 200,000 API calls, and the rates get better for larger packages. For special use cases, we can work on tailoring a custom plan that meets your needs.
If you want to extract data through proxies from a specific location, you have quite a few options. The datacenter proxy pool is split among 7 countries, while residential IPs can be chosen from 40 different areas. If that’s not enough, you can opt for a custom package with the option of adding 195 other locations to your roster.
2. Oxylabs
Oxylabs took an interesting approach with IP rotation. Typically, when you choose a package, you have to rotate the IPs on your own, but you have the option of also buying their proxy rotator as an add-on.
While some use cases may not depend much on rotating proxies, it’s imperative in data extraction, so if you choose Oxylabs proxies, get the rotator too.
The company offers separate packages for residential and datacenter proxies. Residential IP usage is priced based on used bandwidth, with the lowest plan starting at $300 per month for 20 GB of traffic. Datacenter proxies have unlimited bandwidth, and the packages differ in how many IPs you get. Those start at $160 per month, and you have to choose between 100 US IPs or 60 non-US IPs.
In total, they have over 100 million residential proxies and 2 million datacenter proxies. So, you’re unlikely to run out of IPs.
The proxy pool is spread over an impressive area - 186 different locations. Though all those countries have residential IPs, don’t expect all of them to have datacenter proxies too.
3. Shifter

Shifter leverages the state-of-the-art infrastructure behind datacenter proxies to its full extent. As a result, they also offer shared datacenter proxies besides the dedicated IP option you’ve come to expect.
Something we like about Shifter’s offer is the large number of packages to choose from. For example, the smallest shared proxy plan starts at $30 per month to access 10 shared proxies. On the other end of the spectrum, you can get 1000 shared proxies for $2000. In short, you have options.
Dedicated datacenter proxies are expectedly pricier, with the cheapest package starting at $25 for 5 IPs only you have access to.
If you’re interested in residential IPs, the prices start at $250 per month for 10 special backconnect proxies, meaning a server handles proxy rotation, so you don’t have to bother.
Their proxy pool contains more than 31 million IPs, and users can see the exact number in their control panel.
Geo-targeting is available for any country in the world, but there’s a caveat - you can only use it with residential IP addresses.
4. SmartProxy

Besides its impressive proxy pool, SmartProxy comes with a nice selection of tools. These are a proxy address generator, add-ons for Chrome and Firefox, and a program that helps you surf the net from multiple browsers simultaneously.
But let’s get back to proxies. Smartproxy offers its users access to over 40 million residential IPs as well as 40k datacenter proxies. Besides those, they also provide unique residential proxies designed for search engine scraping. Unlike the other two options, whose price depends on used bandwidth, search engine proxy packages have a fixed number of requests.
While most IPs are from the US, UK, Canada, Germany, India, and Japan, they have more than a hundred locations with at least 50 IPs.
Price-wise, you’re looking at packages that start at $50 for 100 GB of traffic through datacenter proxies or 75$ for 5 GB with residential proxies. As you’d expect, more extensive plans have more advantageous deals.
5. Bright Data

Bright data brings to the table an impressive proxy pool composed of datacenter, residential and mobile proxies. In numbers, it looks like this:
- 700,000+ datacenter IPs
- 72,000,000+ residential IPs
- 85,000+ static residential IPs
- 7,500,000+ mobile IPs
Large numbers, to be sure. The downside is that the prices are pretty steep too. While there are some packages with set prices, it’s best to use the pricing calculator to create a custom plan for yourself. With this calculator, you set how many IPs you want and a maximum bandwidth per month, and you’ll receive the exact price.
On the topic of geo-location, Bright Data has IPs in just about any country around the globe. They have a page on their website where you can check locations. If you need certain types of proxies in specific areas, that page will be handy.
How to choose a proxy service provider
One of the most significant advantages of web scraping and proxies, in general, is the wealth of options.
As most people or businesses have a specific goal in mind, it’s not unusual to choose a provider and then realize that it’s not a good fit. It’s not ideal, but it happens. Luckily, most companies have a trial period, a free package, or at least a money-back policy.
As such, the best advice I can offer you is to explore your options, window shop, and you’re bound to find something that’s right for you.
Besides proxies, you’ll also need a web scraper, right? Well, out of all the alternatives, here are 10 data extraction products that deserve your attention.
If you don’t have the time, here’s an abridged recommendation, just for you: start your WebScrapingAPI free trial, and you won’t need to try other scrapers!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Explore the transformative power of web scraping in the finance sector. From product data to sentiment analysis, this guide offers insights into the various types of web data available for investment decisions.


Comparing Cheerio and Puppeteer for web scraping? Features, benefits, and differences covered. Tips included. Choose the best tool for you.