How to Scrape Website Sitemaps For Better Efficiency
Robert Munceanu on May 20 2021

Hello and welcome back to our web scraping show! In today’s episode, we will find out how price optimization can help our business grow by scraping a website using its sitemaps.
If you want to know what will happen next, grab a seat, and some snacks, and keep watching, I mean, reading!
Why you’ll need product data
Using public information for one’s business growth is a common practice among business owners around the world.
Price intelligence, competitor monitoring, revenue optimization, and other solutions to help your business prosper can be acquired by using a web scraping tool. Imagine how much time it would take to copy and paste the information of hundreds of products into a table. This is where WebScrapingAPI changes the game rules.
The classic way to gather information with a web scraping tool
Let’s say you want to scrape the products of a website en masse. One way of using a web scraping tool is manually selecting each product page URL for the tool to scrape. This means you must do some research on the website and see where each product page is located and so on.
If the website has only a few dozen pages, it can be manageable, but what if the website has hundreds or even thousands of pages? The work could get a bit tedious, take a lot of time, and be unpleasant as well.
What can we do in such a situation?
The faster way to do it
Sitemaps. What are they?
Sitemaps can be beneficial when we are talking about SEO. They are like a website’s blueprint, helping search engines find, crawl, or even index all of your website’s content.
Usually, they are used by huge websites to structure their pages better and help search engines identify the most important pages from the least ones.
Can we use these sitemaps to our advantage when scraping? Of course! Let’s find out how they can help us scrape a website’s content en masse.
Let’s try the method out!
For us to make use of WebScrapingAPI, we need to create our account and gain our private access key used to authenticate with the API. You don’t have to worry, as creating your account is free, and you don’t need to add your card or other personal information.
When logging in, we will be redirected to the Dashboard. Here, we will see our access key which we will make use of in a few moments. Make sure to keep it for yourself, but if you think that your private key has been compromised, you can always reset it by pressing the “Reset API Key” button.
For more details about how WebScrapingAPI works and how it can be integrated within your project, you can always see its documentation, and to test things out, the API Playground helps you visualize the results even better!
Enough with the presentation, let’s see how we can use WebScrapingAPI to scrape by using sitemaps.
For this example, we will use NodeJS as our programming language, but you can use whichever programming language you are comfortable with. Then, we will scrape the sitemap and parse its product URLs, scrape the product pages, and store the data in a csv file. This way, you can scrape en masse using WebScrapingAPI, but if you wish to scrape only certain pages, you can make specific requests as well.
1. Find sitemap URLs
In this example, we will be looking at Maplin’s sitemaps, which can be found at the bottom of their robots.txt.
By following the URL above, we will be redirected to the XML containing the sitemap links.
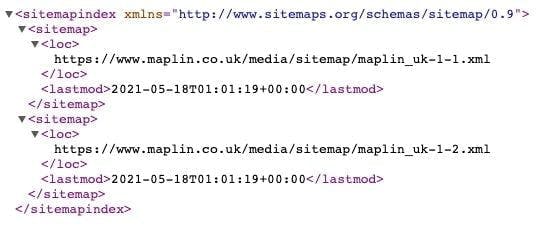
If we follow the first link from above, we will get to the sitemap of different pages, some of which are product pages! Those are the pages which we will extract data from and save it into a CSV file for later use. Sounds simple, doesn’t it?

2. Identify the selectors
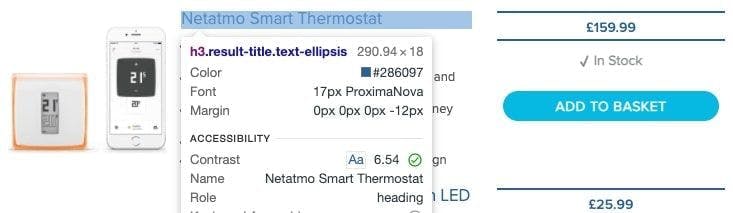
In order to extract only the data we need, we have to know where it is located. To do that, let’s visit the smart lighting switches URL from above and use the inspect developer tool.
We notice that each product in the list is located under a li tag with the class ais-Hits-item.
Inside this node, we see that the title and price are under the h3 tag with the class result-title and the span tag with the class after_special price respectively.
3. Install necessary packages
This step is rather simple; just install this set of packages:
- jsdom: helpful when it comes to HTML parsing.
- got: this package will help us make the HTTP request to WebScrapingAPI.
- xml2js: will parse the xml and convert it into an object for easier usage.
- csv-writer: to store the extracted data into a csv file.
To install all of these packages, simply use this command line in your projects’ terminal:
npm install jsdom got xml2js csv-writer
4. Prepare parameters for the request
Here we will make use of one of WebScrapingAPI’s features to render the page and wait for all of its contents to load. This way we can get ahold of more data. Don’t forget to add your private access key and the URL you want to scrape, in our case, the sitemap URL containing the links to product pages.
const api_url = "https://api.webscrapingapi.com/v1"
const url = "https://www.maplin.co.uk/media/sitemap/maplin_uk-1-1.xml"
let params = {
api_key: "XXXXX",
url: url,
render_js: 1,
wait_until: 'networkidle2'
}
5. Make the request and parse the resulting XML string
After getting the result from the API, we need to convert the xml string into an object.
const response = await got(api_url, {searchParams: params})
const parser = new xml2js.Parser()
parser.parseString(response.body, async function (err, result) {
// the rest of the code
}The next step will be to iterate through the product URLs, create a request for each of them to extract the product data and select which information we need to store.
6. Iterate, request, select
We won’t need to iterate through all the URLs of the sitemap for this example, so let’s only take the URLs from position 5 to 10. Next, we’ll prepare the parameters for the API request and use JSDOM to parse the resulting HTML.
To select the title and price of the product, we saw earlier that they are found inside the h3 tag with the class result-title and the span tag with the class after_special price, respectively.
After creating an object with the title and price we just extracted, we push it to the products array.
The code should look something like this:
let products = []
for (let index = 5; index < 10; index++) {
params.url = result['urlset']['url'][index]['loc'][0]
const res = await got(api_url, {searchParams: params})
const {document} = new JSDOM(res.body).window
const elements = document.querySelectorAll('li.ais-Hits-item')
if (elements) {
elements.forEach((element) => {
let element_obj = {}
const title = element.querySelector('h3.result-title')
if (title && title.innerHTML) element_obj.title = title.innerHTML
const price = element.querySelector('.after_special.price')
if (price && price.innerHTML) element_obj.price = price.innerHTML
if (element_obj && element_obj.title && element_obj.price)
products.push(element_obj)
})
}
}
7. Store the extracted data
Here is where we use the csv-writer library to help us convert a list of objects into a csv file.
Simply specify the path and name of the file soon to be created, and the headers array, which consists of column objects, where the id represents the properties of the product objects and the title is the column’s name.
const csvWriter = require('csv-writer').createObjectCsvWriter({
path: 'products.csv',
header: [
{id: 'title', title: 'Product Name'},
{id: 'price', title: 'Product Price'}
]
})
csvWriter.writeRecords(products).then(() => console.log('Success!!'))8. You are done!
We have successfully extracted data using sitemaps to navigate through a website’s product pages, congratulations! Here is the full view of the code:
const {JSDOM} = require("jsdom");
const got = require("got");
const xml2js = require("xml2js");
(async () => {
const api_url = "https://api.webscrapingapi.com/v1"
const url = "https://www.maplin.co.uk/media/sitemap/maplin_uk-1-1.xml"
let params = {
api_key: "XXXXX",
url: url,
render_js: 1,
wait_until: 'networkidle2'
}
const response = await got(api_url, {searchParams: params})
const parser = new xml2js.Parser()
parser.parseString(response.body, async function (err, result) {
let products = []
for (let index = 5; index < 10; index++) {
params.url = result['urlset']['url'][index]['loc'][0]
const res = await got(api_url, {searchParams: params})
const {document} = new JSDOM(res.body).window
const elements = document.querySelectorAll('li.ais-Hits-item')
if (elements) {
elements.forEach((element) => {
let element_obj = {}
const title = element.querySelector('h3.result-title')
if (title && title.innerHTML) element_obj.title = title.innerHTML
const price = element.querySelector('.after_special.price')
if (price && price.innerHTML) element_obj.price = price.innerHTML
if (element_obj && element_obj.title && element_obj.price)
products.push(element_obj)
})
}
}
const csvWriter = require('csv-writer').createObjectCsvWriter({
path: 'products.csv',
header: [
{id: 'title', title: 'Product Name'},
{id: 'price', title: 'Product Price'}
]
})
csvWriter.writeRecords(products).then(() => console.log('Success!!'))
})
})();Give it a try yourself!
I hope this tutorial has been helpful and made it easier for you to understand how simple it is to use sitemaps to our advantage regarding web scraping.
It is even less time-consuming, and this way you won’t miss out on pages as you would normally do when manually navigating a website.
When it comes to scraping en masse, it’s clear that using sitemaps is a far better solution than manually selecting each product page or even using a spider to crawl the website.
Until the next episode of our web scraping show, how about you give WebScrapingAPI a try? You can test it out with up to 1000 free API calls. See you next time!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Learn how to use Playwright for web scraping and automation with our comprehensive guide. From basic setup to advanced techniques, this guide covers it all.


Unlock the power of automation and extract valuable data from the web with ease. This article will guide you through the process of using the Parsel library in Python to scrape data from websites using CSS and XPath selectors.


Master web scraping with Scrapy. Learn step-by-step with practical examples in this comprehensive guide. Join the data extraction big leagues now!