Web Scraping in Ruby: The Ultimate Tutorial
Raluca Penciuc on Jan 15 2023
Let's not sugarcoat this, as the years drag on, the Internet's data volume will only continue to rise. The situation is beyond anyone's control, but is that really a bad thing?
Particularly in the past decade, web scraping has gained enormous popularity. To succeed in today's business world, companies need proper strategies, which require ample information within a short amount of time. Plus, it could be a neat way for developers to improve their coding skills AND help the company.
If you play for team Ruby but don't have much to do with web scraping, this article will provide you with a new niche to explore: building your own web scraper.
Understanding web scraping
Let's take a price comparison platform as an example. Its job is to get the cost of a multitude of items from several online retailers. But why stop at physical products? The airline and hospitality industries have also become a lot more consumer-friendly, thanks to comparison sites. So, how do these magical websites or apps function? Through web scraping, of course!
You are likely wondering now, "How else will I use this data?". So let's have a look at some of the practical applications of web scraping:
- Real estate agencies require data on properties, neighborhoods, and whole areas to make the best deals
- Sales and marketing leads need branding and pricing data from their competitors to create competitive strategies
- Companies must generate leads to find clients if it hopes to stay in business
This well-written article that discusses web scraping provides detailed descriptions and additional use cases.
Web scrapers are not easy to create, even if you understand how it works and the potential benefits it can provide. There are many ways through which websites can identify and block bots from accessing their data.
As examples, here are some:
- Geo-blocking: You might be shown regionally specific results when asking for information from another area (e.g., airplane ticket prices).
- IP Blocking: A website can block or slow you down when it determines you are making repeated requests from a particular IP address;
- Honeypots: Humans cannot see honeypot links, but bots can; once the robots fall for the trap, their IP address is blocked;
- CAPTCHAs: People can solve these simple logical problems relatively quickly, but scrapers often find them difficult;
It is no easy task to overcome all these obstacles. It isn't all that difficult to build a simple bot, but creating an excellent web scraper is a bit more challenging. Therefore, over the past decade, APIs for web scraping have become one of the hottest topics.
HTML content from any website can be collected using WebScrapingAPI, and all the problems we mentioned earlier will be automatically addressed. Additionally, we use Amazon Web Services to ensure speed and scalability. Sounds interesting, right? Well, don't just stop at sound! Try it for yourself with the 5000 free API calls you get as part of the free WebScrapingAPI trial.
Understanding the Web
It is necessary to understand Hypertext Transfer Protocol (HTTP) to understand the Web. It explains how a server and a client communicate. A message contains information that describes the client and how it handles data: method, HTTP version, and headers.
For HTTP requests, web scrapers use the GET method to retrieve data from the server. Additionally, there are some advanced methods such as POST and PUT. The HTTP methods are detailed here for your reference.
In HTTP headers, a variety of additional information can be found about requests and responses. For web scraping, these are the ones that matter:
- User-Agent: web scrapers rely on this header to make their requests seem more realistic; it contains information such as the application, operating system, software, and version.
- Cookie: the server and request can exchange confidential information (such as authentication tokens).
- Referrer: contains the source site the user visited; accordingly, it is essential to consider this fact.
- Host: it identifies the host that you are connecting to.
- Accept: provides a response type for the server (e.g., text/plain, application/json).
Understanding Ruby
Ruby is a high-level multiparadigm programing language that is also fully interpretable. This means that the program code is stored in plain text, which is transmitted to the interpreter that executes it.
In 1995, Yukihiro Matsumoto (also known as Matz in the Ruby community) combined features of different programming languages such as Perl, Lisp, and Smalltalk to create a new one that focuses on simplicity and productivity.
It's a niche programming language, its natural area being web applications. Here are the significant advantages you benefit from using this language in your projects:
- It gets results, fast. In combination with the Rails framework, you can create software relatively quickly; that is why startups mainly prefer Ruby to promptly build their MVPs (Minimum Viable Product).
- It's well-developed and maintained by the growing Ruby community.
- Helpful tools and libraries (called gems) ensure that it's easy to follow the best coding practices in almost any situation.
On the other hand, these advantages do not make Ruby a magical universal solution to every new software. You may also consider these characteristics of the language before making a decision:
- As their size grows, applications built with Ruby get slower, which causes problems to scalability.
- Its natural area is web applications. Therefore, it is not well suited for desktop/mobile applications.
- Because it uses an interpreter, a possible Object-Oriented code will be slower.
Making your own web scraper
Now we can start talking about extracting data. First things first, we need a website that provides valuable information.
Step 1: Set up the environment
To build our Ruby web scraper, we need first to make sure that we have all the prerequisites:
- The latest stable version of Ruby: check out their official installation guide to choose the best method for your operating system.
- An IDE: in this guide, we will use Visual Studio Code, as it is lightweight and there is no need for additional configurations, but you can choose whatever IDE you prefer.
- Bundler: a dependency management Ruby tool (also called a gem);
- Watir: a Selenium powered gem used for automatic testing, as it can imitate user's behavior on a browser;
- Webdrivers: a gem recommended by Watir that will automatically download the latest driver for a browser instance;
- Nokogiri: a gem well-known for the ability to make web pages analysis easy. It can parse HTML, XML, detects broken HTML documents, and offers access to elements by XPath and CSS3 selectors.
After setting up the Ruby environment, create a new directory anywhere on your computer and open it with your IDE of choice. Then run the following command in a terminal window to install our first gem:
> gem install bundler
Now create a file called Gemfile in your project root directory. Here we are going to add the rest of the gems as dependencies:
source 'https://rubygems.org'
gem 'watir', '~> 6.19', '>= 6.19.1'
gem 'webdrivers', '~> 4.6'
gem 'nokogiri', '~> 1.11', '>= 1.11.7'
Now get back to the terminal window and run the following command to install the gems we declared:
> bundle install
Cool setup! Finally, just create a “scraper.rb” file to hold our web scraper’s code. Whatever we write here, we can execute with the command:
> ruby scraper.rb
Step 2: Inspect the page you want to scrape
Great, let’s move on! Navigate to the page you want to scrape and right-click anywhere on it, then hit “Inspect element”. The developer console will pop up, where you should see the website’s HTML.
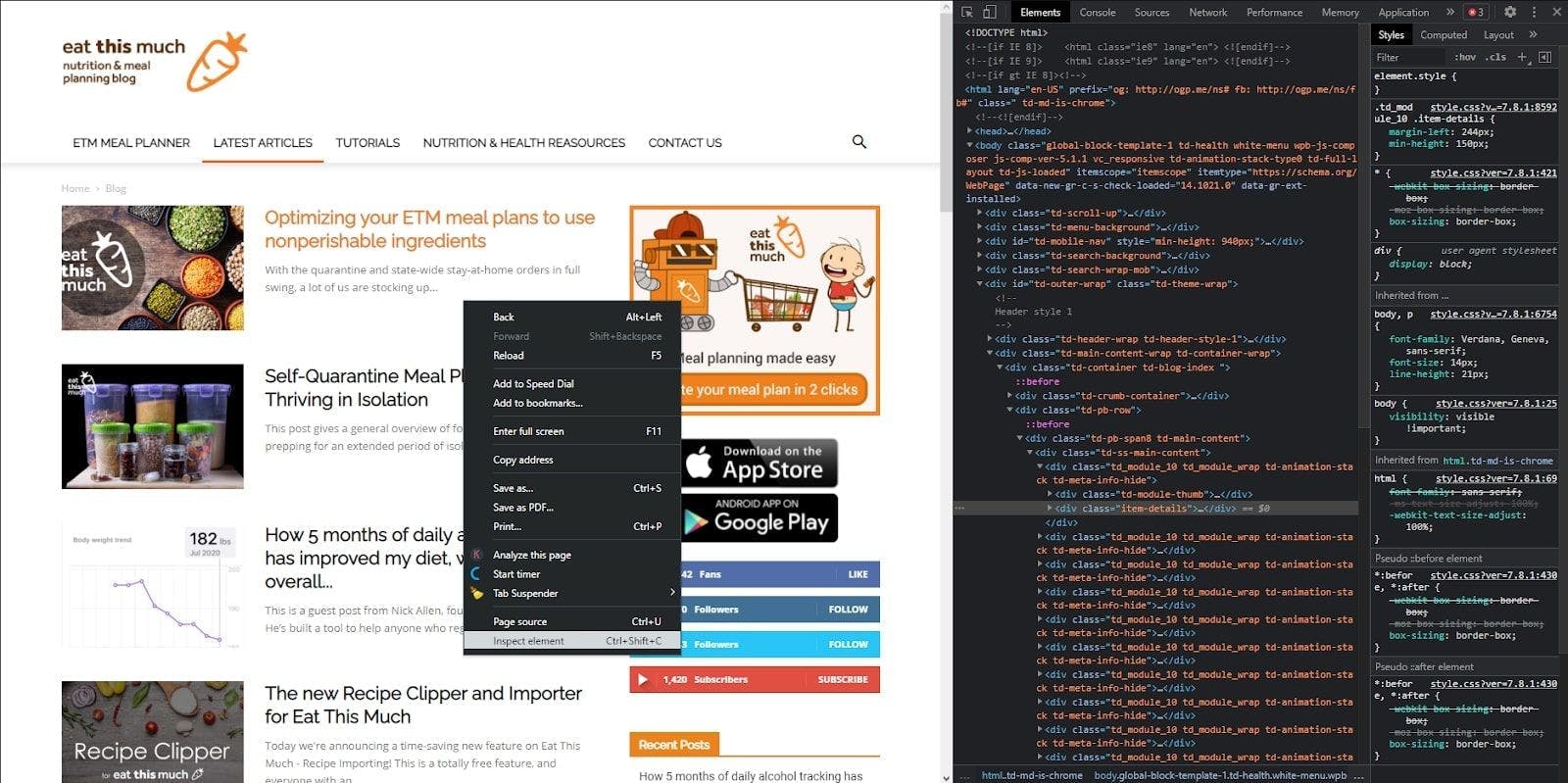
Step 3: Send an HTTP request and scrape the HTML
Now, to get that HTML on our local machine, we have to send an HTTP request using Watir to return the document. Let’s get back to the IDE and put this idea into code.
First, write the imports that we need:
require 'watir'
require 'webdrivers'
require 'nokogiri'
Then we initialize a browser instance and navigate to the website that we want to scrape. We then access the HTML and pass it to the Nokogiri constructor, which will help us to parse the result.
browser = Watir::Browser.new
browser.goto 'https://blog.eatthismuch.com/latest-articles/'
parsed_page = Nokogiri::HTML(browser.html)
File.open("parsed.txt", "w") { |f| f.write "#{parsed_page}" }
browser.close
We also wrote the result in a text file called “parsed.txt” to take a look over the HTML. It’s important to close the connection after receiving the response, as the process will continue running.
Step 4: Extracting specific sections
So, we have an HTML document, but we want data, which means that we should parse the previous response into human-readable information.
Starting with baby steps, let’s extract the title of the website. A remarkable fact about Ruby is that everything is an object with very few exceptions, meaning that even a simple string can have attributes and methods.

Therefore, we can simply access the value of the website’s title through the attributes of the parsed_page object.
puts parsed_page.title
Moving forward, let’s extract all the links from the website. For this, we will use a more generic method that parses specific tags, the css method.
links = parsed_page.css('a')
links.map {|element| element["href"]}
puts linksWe also use the map method to keep only the links with a href attribute from the HTML.
Let’s take a more realistic example. We need to extract the articles from the blog, their title, address, and meta description.
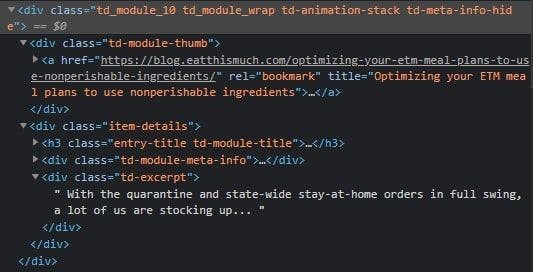
If you inspect one of the article cards, you can see that we can get the address and the article’s title through the link’s attributes. Also, the meta description is under a <div> tag with a specific class name.
Of course, there are many ways to perform this search. The one we’ll use will consist of looking for all the <div> tags with the td_module_10 class name and then iterating through each one of them to extract the <a> tags and the inner <div> tags with the td-excerpt class name.
article_cards = parsed_page.xpath("//div[contains(@class, 'td_module_10')]")
article_cards.each do |card|
title = card.xpath("div[@class='td-module-thumb']/a/@title")
link = card.xpath("div[@class='td-module-thumb']/a/@href")
meta = card.xpath("div[@class='item-details']/div[@class='td-excerpt']")
endYes, as you may have already guessed, an XPath expression is what does the trick because we are looking for HTML elements by their class names and their ascendants.
Step 5: Export the data to CSV
This type of extraction can be beneficial when the data should pass to another application, an article aggregator in our case. So, to do that, we need to export the parsed data to an external file.
We will create a CSV file, as it can be easily read by another application and opened with Excel for further processing. First, just one more import:
require 'csv'
Then we will create the CSV in “append” mode, and wrap the previous code, so now our scraper will look like this:
CSV.open("articles.csv", "a+") do |csv|
csv << ["title", "link", "meta"]
article_cards = parsed_page.xpath("//div[contains(@class, 'td_module_10')]")
article_cards.each do |card|
title = card.xpath("div[@class='td-module-thumb']/a/@title")
link = card.xpath("div[@class='td-module-thumb']/a/@href")
meta = card.xpath("div[@class='item-details']/div[@class='td-excerpt']")
csv << [title.first.value, link.first.value, meta.first.text.strip]
end
endCool, that’s all! Now we can see all the parsed data in a clean, non-scary, and easy to forward way.
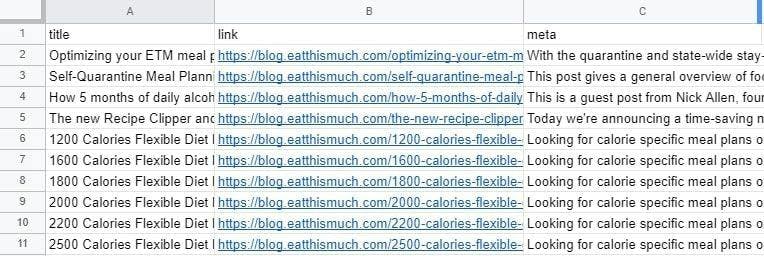
Conclusion and alternatives
We have now completed our tutorial. Congrats! Hopefully, this article gave you a lot of information about web scraping and helped you better understand it.
Obviously, this technology can do a lot more than power article aggregators. The key is finding the correct data and analyzing it to come up with new possibilities.
However, as I stated at the start of the article, web scrapers face numerous challenges. In addition to boosting your business, it is a great learning opportunity for developers to solve issues using their own web scrapers. Nevertheless, you may want to cut costs if you need to complete a project (time, money, people).
An API dedicated to solving these problems will always be easier to use. Even when there may be obstacles such as Javascript rendering, proxies, CAPTHAs, and other blocking factors, WebScrapingAPI overcomes all of them and provides a customizable experience. If you are still unsure, why not try out the free trial option?
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Explore the transformative power of web scraping in the finance sector. From product data to sentiment analysis, this guide offers insights into the various types of web data available for investment decisions.


Discover how to efficiently extract and organize data for web scraping and data analysis through data parsing, HTML parsing libraries, and schema.org meta data.