Cheerio.load not working: This is How to Scrape web with cheerio
WebscrapingAPI on Nov 15 2022
Web scraping is a technique of utilizing robot scripts to provide them with reliable data. Web scrapers are experts in crawling hundreds and thousands of sites within several minutes when properly implemented with the correct programming language and toolset.
It's a powerful way to gain massive amounts of erudition, which can be quickly processed and cleaned for extracting data. Even though, during some situations of counterfeit goods, web scraping tools can be utilized to browse through the online platform to look for all the fake-selling items.
You can easily report them due to the presence of website links. But in the past, it was pretty daunting to search and go through all the websites manually. Although you might want the web scrape data work might look straightforward, it's certainly not. The scraping work is a complicated process that needs technical knowledge.
You will certainly come across tools like ParseHub and Diffbot that should be used with technical knowledge, but in today's article, you will learn about "CHEERIO," why it isn't loaded at times, and various other things.
Cheerio.Load Not Does Work: Why is That?
At times, you will find the cheerio.load not working correctly. You're well aware that there is an issue, but you cannot figure out where it is. Remember one thing, the "<tbody" component should be the child of the "<table> component. If you don't get these things corrected, the Cheerio.load will not work.
In the current version of Cheerio parses markup, the parser itself does not recover from that particular error. You have to write a valid HTML string, which means you have to wrap the string in "</table> and "<table>. When you downgrade to Cheerio 0.22.0, its parsers will take care of it.
Cheerio: Things You Need to Know
So, what exactly is Cheerio? Well, it's a lean, flexible and fast implementation for a specific server. You might think about what's the need for Cheerio when you have the "Puppeteer," which is a Node.JS-based scraping device.
It's because Puppeteer is used a lot more for automating the browser work and supports the real-time internet's visual surfing in the form of script runs. Puppeteer will work perfectly with all the websites created from React and Angular. You can also make PDFs and take screenshots with Puppeteer.
But when it comes to speed, nothing can beat Cheerio. It's a minimalist tool for doing the scraping work, and you can also combine it with various other modules to create an end-to-end script. This particular script will save up the output in the CSV and also return all other things as well.
Cheerio is certainly a perfect option for scraping work. It will also work with the HTML document and Chrome smoothly. You will not experience any issues while using it, but you need to know how it functions before you utilize it.
How Can You Scrape Out Data With Cheerio?
When it comes to scraping data with the help of Cheerio, you need to follow these methods:
Step 1: Mkdir country-popular cd country-popular npm init
Step 2: npm install Cheerio Axios npm install -D typescript esbuild esbuild-runner
Step 3: "scripts" : [ "scrape": "esr./src/index.ts"]
Step 4: import cheerio from "cheerio"; const $ = Cheerio
Step 5: const firstHeader = $('h2.primary'); console
Step 6: npm run scrape
How to Get Data From a Different Website?
Do you wish to object to data/information from a different site? Follow these 5 steps to do so:
- You need to inspect the website HTML that you wish to crawl
- Access the website's URL by utilizing the code and then download the HTML document and its contents on the page.
- For the content into a readable format
- After that, you need to extract all the helpful information and save it in the form of a structured format.
How to Parse a Node JS HTML File?
You can utilize the npm modules htmlparser and jsdom to conduct a parser and develop a DOM in Node JS. Other options you can opt for are:
- CsQuery for
- You can easily convert XHTML from HTML and utilize XSLT
- BeautifulSoup for Python
- HTMLAgilityPack for
Scraping WebPages in Node with Cheerio: How to Do It?
Under this particular section, you will understand how to scrape a web page with the help of Cheerio. But before you opt for this append method, you need to have permission for it. Otherwise, you might find yourself violating privacy, breaching copyright, or the terms of services.
You will learn how you scrape the ISO 3166-1 alpha-3 code for all the nations and various other jurisdictions. You will find the country data under the codes area of the ISO 3166-1 alpha-3 page. So now, let's get started!
Step 1: Make a Working Directory

Here, you have to make a director for the project by running the command "mkdir learn-cheerio" on the terminal area. This particular command will develop a directory, which is known as "learn-cheerio," and you're also free to provide it with a
In this step, you will make a manual for your assignment by executing a command on the terminal. The command will create a manual called learn-cheerio. You can provide it with a separate name if you wish.
You will certainly see a folder with the name "learn-cheerio" made after properly running the selected elements or the "mkdir learn-cheerio" command. After the directory is created and you can successfully load external resources, you need to open the director and a text editor to initialize the project.
Step 2: Initializing the Project
To make sure that Cheerio implements properly with this project, you have to navigate the project directory and then initialize it. You just need to open the directory through the text editor you like and then initialize it by running the "npm init -y" command. Once you complete this process, you can make a "package.json file" at the heart of the project directory.
Step 3 - Install the Dependencies

Here, in this section, you will install the project dependencies by running the "npm I Axios cheerio pretty."
When you use this command, it will take some time to load, so please be patient. Once you run the command successfully, you can register three dependencies within the package.json file right under the dependencies section.
The 1st dependency is known as "Axios," the 2nd one is "Cheerio," and the last one is "Pretty. Axios is a well-known HTTP client that functions in the browser and node. You will need it because Cheerio is viewed as a markup parser.
So, to make sure that Cheerio gets to parse the makeup and then scrape the data that you need, you have to use
To ensure Cheerio gets to parse the markup and then scrape the data you need, you must utilize Axios to obtain the markup from the site. You can use a different HTTP client to fetch the markup if you wish. It doesn't necessarily have to be Axios.
"Pretty," on the other hand, is an npm package to beautify the markup so that it's completely readable when it's printed on the terminal.
Step 4: Inspect the Website Page You Wish to Scrape
Right before you scrape the data from the webpage, you need to first have a good understanding of the HTML resulting data structure of the page. Under this section
Before you scrape data from a webpage, it's vital to understand the HTML structure of the page from where you will be scraping data. On Wikipedia, go to the ISO 3166-1 alpha-3 code. Beneath the "current code" section, you will find a list of nations and their codes.
Now, you just have to open the DevTools by clicking on the key combination of "CTRL + SHIFT + I. Otherwise, you can right-click and then choose the "Inspect" option. Here is an image that shows how the "list" appears on the DevTools
Step 5: Write the Code to Scrape Out the Data
Now, you need to write down the code to scrape the data. To begin the work, you must run the "touch app.js" to assemble the app.js file. If you run this command successfully, you can create the app.js file within the project directory without any error.
Just like all the other Node packages, you have to get pretty, Cheerio, and anxious before you begin utilizing them. To do so, you need to add the following code:
const axios = require ["axios"]
const Cheerio = require ["cheerio"]
const pretty = require ["pretty"]
Make sure to provide these codes right at the top of the app.js file. Be sure to have good knowledge of cheerio right before you scrape out the data. You can parse-up the markup by manipulating the resulting data structure. Doing so will help you learn about the cheerio syntax and also the common process. Here is the markup of the UL element that contains the LI elements:
const URL markup = `
<ul class ="fruits">
<li class="frutis__mango"> Mango </li>
<li class="fruits__apple"> Apple </li>
</ul>
You can easily add this particular variable command to the app.js file.
How WebScrapingAPI Can Help?
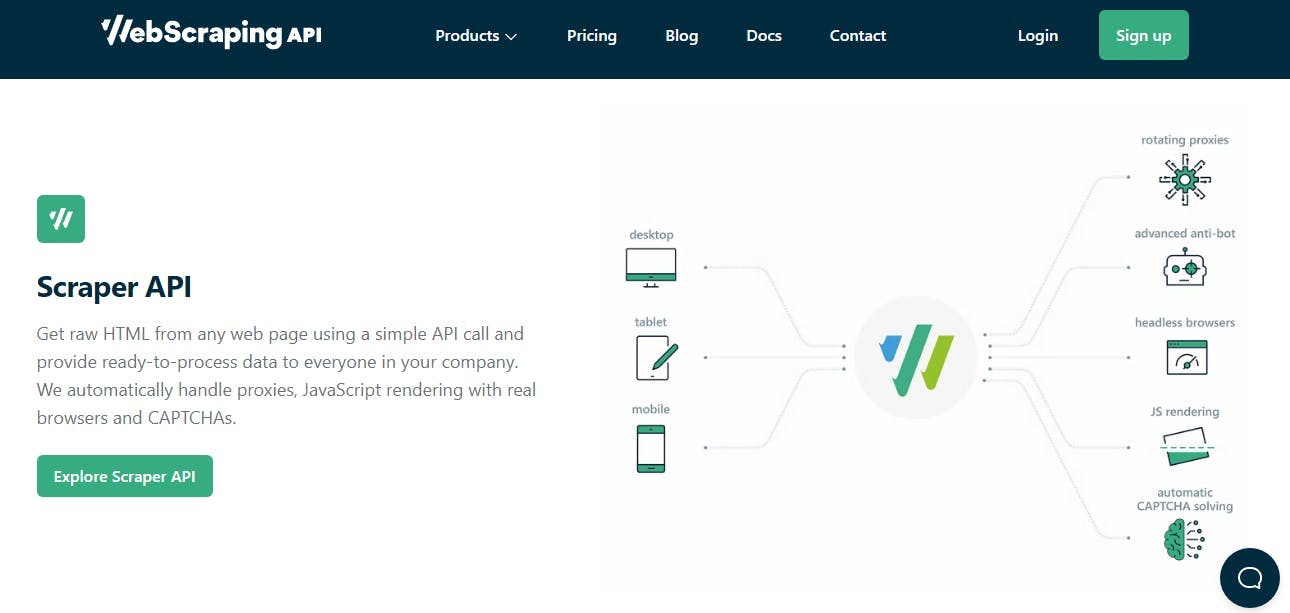
By now, you already gain information on how to use Cheerio, the reason why Cheerio.load doesn't work, the div element, the text content, node, and load HTML. Even though Cheerio is an excellent web-scraping device, others are out there. But the one that stands out among the rest is the WebScrapingAPI software.
This scraping software is utilized by over 10,000 businesses to clean, web scrape, and collect all the useful data. Through this software, you can easily obtain raw HTML from any type of web page, and it utilizes a simple API. It can offer ready-to-process data for all the people in your corporation.
The software will take care of the proxy's JavaScript and visual rendering automatically through CAPTCHAs and real browsers. The software will certainly help grow your business, and its customer support team will be available 24x7 to provide the help you need. Compared to other Scraping API software, this particular software will collect data 3 times faster.
WebScraping API will also enable you to scrape a web page within Vue, AngularJS, React, and various other JS libraries. You will also come across Amazon Scraper API, Google Search and Results API,
Pros:
- It comes with excellent customer support
- Easy-to-use software
- Has ant-bot detection
- Rotating Proxies
Cons:
I didn't find any cons while using the software
Choose WebScrapingAPI: Best Web Scraping Software

Web crawling and scraping are pretty important in today's world. The work is conducted by experts who have a good knowledge of scraping sites without many errors. The scraping work can help you extract out data that you need. But having software like WebScrapingAPI can make the extraction a lot faster.
The software gained popularity as a leading software in scraping out websites. Businesses that utilize this scraping software obtain over 50 million each month. The software is also utilized with state-of-art technology that makes it stand out among the other tools.
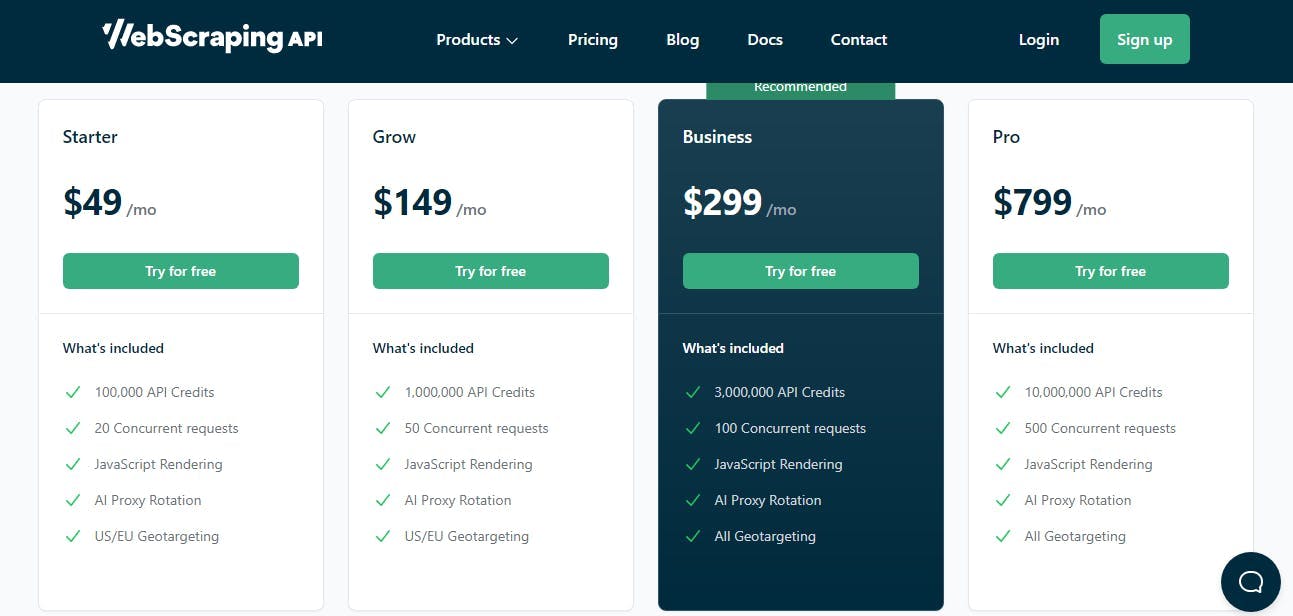
Through the platform, you can make price comparisons, lead generation, monetary data, market research, and many other things. So, are you interested in this site scraping tool to collect data? You can call the experts from WebScrapingAPI now! Using their software will prevent blocked requests, and you will receive excellent service.
Also, be sure to check out the pricing options. You will come across types of plans, which begin from $49. Be sure to do a bit of research and check on the price right before you start utilizing the software.
Use WebScrapingAPI today!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Explore the transformative power of web scraping in the finance sector. From product data to sentiment analysis, this guide offers insights into the various types of web data available for investment decisions.


Dive into the transformative role of financial data in business decision-making. Understand traditional financial data and the emerging significance of alternative data.