How to Build a Web Crawler in Less than 100 Lines of Code
Raluca Penciuc on Aug 13 2021
We live in a digital age, and we have access to a ton of data. Using this information, we can better understand how we work, play, learn and live. Wouldn't it be nice to be able to get more targeted information on a particular topic?
With this article, we will demonstrate how to use BeautifulSoup and WebScrapingAPI together to build our own crawlers for gathering targeted data from websites.
A word of warning: scraping copyrighted content or personal information is illegal in most cases. To stay safe, it’s better to get explicit consent before you scrape any site, especially social media sites.
What are web crawlers
There are numerous search engines out there, and we all use them. Their services are easy to use - you just ask about something, and they look everywhere on the web to find an answer for you. Behind the curtain, it is Google's Googlebot crawler that makes Google's search engine such a success.
By scanning the web for pages according to your input keywords, crawlers help search engines catalog those pages and return them later on through indexing. Search engines rely on crawlers to gather website information, including URLs, hyperlinks, meta tags, and articles, as well as examining the HTML text.
Due to the bot's ability to track what it has already accessed, you don't have to worry about it getting stuck on the same web page indefinitely. The Public Internet and content selection present several challenges to web crawlers. Every day, existing websites post dozens of new pieces of information and do not even get me started on how many new websites appear daily.
In the end, this would require them to search through millions of pages and refresh their indexes continually. The systems that analyze website content depend on them, so they are essential.
So, crawlers are important, but why mention them? Because we’ll build our own bot to help out in the data extraction process. This way, we can rely on it to fetch URLs instead of typing them into the scraper manually. More automation, woo!
Installation
Now that we have a basic understanding of web crawlers, you may wonder how this all looks in action. Well, let’s dig into it!
First things first, we need to set up our work environment. Make sure your machine matches the following prerequisites:
- python3;
- A Python IDE. This guide will use Visual Studio Code because it’s lightweight and doesn’t require any additional configuration. The code is IDE-agnostic still, so you can choose any IDE you are comfortable with;
Last but not least, we will need an API key. You can create a free WSA account, which will give you 5000 API calls for the first 14 days. Once you registered, simply navigate to your dashboard, where you can find your API key and other valuable resources.
Developing the crawler
Good, we have the tools, so we are closer to start building our crawler. But how are we going to use it? Its implementation may differ depending on our final goal.
Pick a website and inspect the HTML
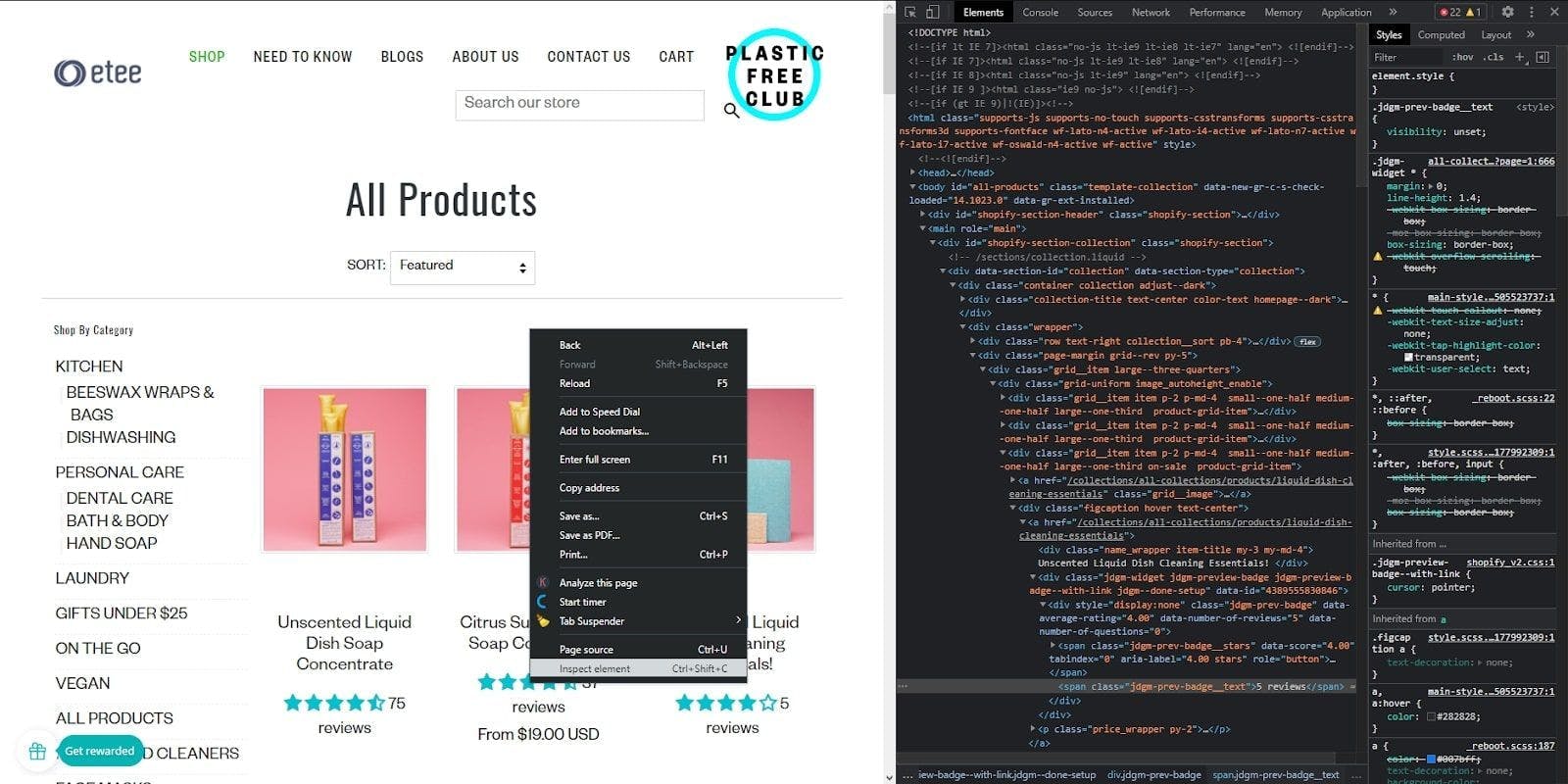
For this tutorial, we chose an e-commerce website that sells zero-waste products of different uses. We will navigate through all the pages, extract the product list of each page and finally store the data in a CSV file for every page.
To do that, we have first to take a look at the page structure and decide our strategy. Right-click anywhere on the page, then on “Inspect element”, and the “Developer Console” will pop up. Here you can see the website’s HTML document, which holds all the data we need.
Build the crawler
Ok, now we can write some code!
Begin by opening a terminal window in your IDE and run the following command, which will install BeautifulSoup, a library to help us extract the data from the HTML:
> pip install beautifulsoup4
Then, create a folder named “products”. It will help organize and store the scraping results in multiple CSV files.
Finally, create the “crawler.py” file. Here we are going to write all our code and crawling logic. When we are done, we can execute the file with the following command:
> py crawler.py
Moving forward, let’s import the libraries we need and then define some global variables:
import requests
from bs4 import BeautifulSoup
import csv
BASE_URL = "https://www.shopetee.com"
SECTION = "/collections/all-collections"
FULL_START_URL = BASE_URL + SECTION
ENDPOINT = "https://api.webscrapingapi.com/v1/"
API_KEY = "API_KEY"
Now, let’s define the entry point for our crawler:
def crawl(url, filename):
page_body = get_page_source(url, filename)
soup = BeautifulSoup(page_body, 'html.parser')
start_crawling(soup, filename)
crawl(FULL_START_URL, 'etee-page1.txt')
We implement the crawl function, which will extract the HTML documents through our get_page_source procedure. Then it will build the BeautifulSoup object that will make our parsing easier and call the start_crawling function, which will start navigating the website.
def get_page_source(url, filename):
params = {
"api_key": API_KEY,
"url": url,
"render_js": '1'
}
page = requests.request("GET", ENDPOINT, params=params)
soup = BeautifulSoup(page.content, 'html.parser')
body = soup.find('body')
file_source = open(filename, mode='w', encoding='utf-8')
file_source.write(str(body))
file_source.close()
return str(body)
As stated earlier, the get_page_source function will use WebScrapingAPI to get the HTML content of the website and will write in a text file in the <body> section, as it’s the one containing all the information we are interested in.
Now, let’s take a step back and check how to achieve our objectives. The products are organized in pages, so we need to access each page repeatedly to extract them all.
This means that our crawler will follow some recursive steps as long as there are available pages. To put this logic in code, we need to look at how the HTML describes these conditions.
If you get back to the Developer Console, you can see that each page number is actually a link to a new page. More than that, considering that we are on the first page and we don’t have any other before this, the left arrow is disabled.

So, the following algorithm has to:
- Access the page;
- Extract the data (we will implement this in the next step);
- Find the pagination container in the HTML document;Verify if the “Next Page” arrow is disabled, stop if it is and if not, get the new link and call the crawl function for the new page.
def start_crawling(soup, filename):
extract_products(soup, filename)
pagination = soup.find('ul', {'class': 'pagination-custom'})
next_page = pagination.find_all('li')[-1]
if next_page.has_attr('class'):
if next_page['class'] == ['disabled']:
print("You reached the last page. Stopping the crawler...")
else:
next_page_link = next_page.find('a')['href']
next_page_address = BASE_URL + next_page_link
next_page_index = next_page_link[next_page_link.find('=') + 1]
crawl(next_page_address, f'etee-page{next_page_index}.txt')
Extract data and export to CSV
Finally, let’s check out how we can extract the data we need. We’ll take another peek at the HTML document, and we can see that we can access the valuable information by looking at the class names.
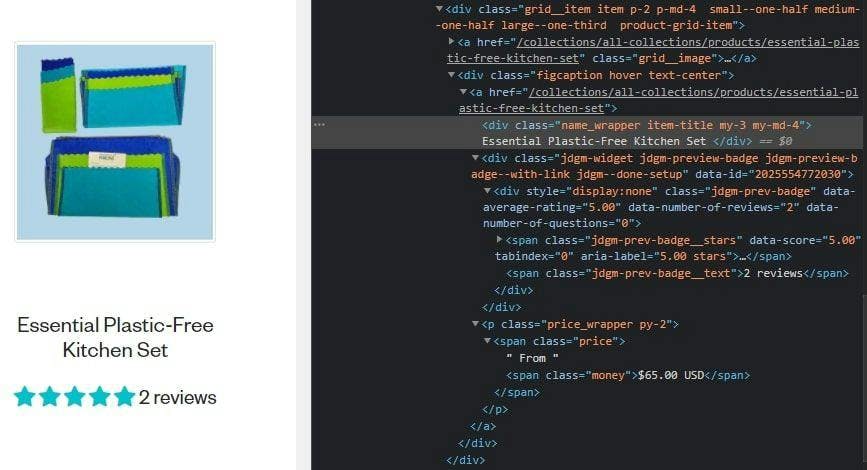
We will extract the product’s name, rating, number of reviews, and price, but you can go as far as you want.
Remember the “products” folder we created earlier? We will now create a CSV file to export the data we scrape from each page. The folder will help us organize them together.
def extract_products(soup, filename):
csv_filename = filename.replace('.txt', '.csv')
products_file = open(f'products/{csv_filename}', mode='a', encoding='utf-8', newline='')
products_writer = csv.writer(products_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
products_writer.writerow(['Title', 'Rating', 'Reviews', 'Price on sale'])
products = soup.find_all('div', {'class': 'product-grid-item'})
for product in products:
product_title = product.find('div', {'class': 'item-title'}).getText().strip()
product_rating = product.find('span', {'class': 'jdgm-prev-badge__stars'})['data-score']
product_reviews = product.find('span', {'class': 'jdgm-prev-badge__text'}).getText().strip()
product_price_on_sale = product.find('span', {'class': 'money'}).getText()
products_writer.writerow([product_title, product_rating, product_reviews, product_price_on_sale])
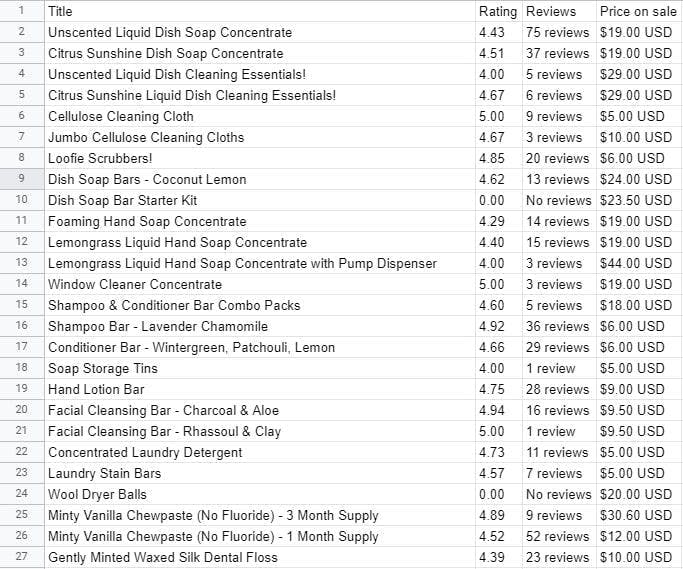
After running the program, you can see all the extracted information in the newly created files.
Closing thoughts
And that’s pretty much it! We just made our own web crawler using Python’s BeautifulSoup and WebScrapingAPI in less than 100 lines of code. Of course, it may differ according to the complexity of your task, but it’s a pretty good deal for a crawler that navigates through a website’s pages.
For this guide, we used WebScrapingAPI's free trial, with 5000 API calls for the first 14 days, more than enough to build a powerful crawler.
It was helpful to focus only on the crawler’s logic instead of worrying about the various challenges encountered in web scraping. It spared us time, energy, and considerable other costs, such as using our own proxies, for example, only a few advantages you can obtain by using an API for web scraping.
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Discover how to efficiently extract and organize data for web scraping and data analysis through data parsing, HTML parsing libraries, and schema.org meta data.


This tutorial will demonstrate how to crawl the web using Python. Web crawling is a powerful approach for collecting data from the web by locating all of the URLs for one or more domains.


Learn how to use Python for web scraping HTML tables: Extract, store & analyze data | Beginner-friendly tutorial
