
Difference Between Web Scraping & Web Crawling
Web browsers are used to exhibit metadata on web pages found on the Internet, which is home to a substantial amount of data. Users can simply move between websites and interpret data using a browser - based display pages.
Web crawling and web scraping are terms used to describe the process of extracting viewpoint code. Web scraping is the process of analyzing a web page and obtaining information from it. Searching for web links and receiving their content iteratively is called web crawling.
Both of these operations are carried out by an application because discovering new connections necessitates web page scraping. Both phrases, which are occasionally used synonymously, refer to the procedure of obtaining information. They serve many purposes, though.
How and where may such knowledge be put to use?
Answers can be found online in greater quantities than the number of websites. This insight can be a valuable tool for creating apps, and understanding how to write such code could be applied to automated web testing.
In this blog, we'll discuss two methods for crawling and scraping the web for data leveraging browsers and basic HTTP requests, in addition to the advantages and disadvantages of each.
Utilizing HTTP Queries And Web Browsers To Download Web Content
Given that almost everything is online nowadays, you can undoubtedly find a module for sending HTTP requests in any programming language. Simple HTTP requests happen quickly. It takes longer to use web browsers like Firefox and Google Chrome as an alternative.
They behave and are presented differently, modifying how each activity is and are shown to be readily legible and used to take into account displaying styles and running scripts on account of web pages. Web browsers occasionally waste resources. For instance, a straightforward HTTP request can be sufficient if you're attempting to retrieve text from a web page & download it as simple text.
Nevertheless, because JavaScript is so widely used, some material on many websites cannot be shown if it is not run. In this case, downloading web content is made easier by using a browser.
CSS and XPath Parsing
XPath and CSS are two methods for parsing text that is often utilized. A query markup language, XPath, is used to identify specific elements in XML and Html files.
Each contains a specific structure, and that pattern can be followed in the writing of a query. CSS selectors are a means to choose elements that use a string pattern and are slightly comparable to XPath because CSS styles are applied on top of HTML structure.
Preparing The Demo
These demos make use of the C# and .NET core 3.1 environments. These APIs must function on.NET 4x as they have not yet altered much recently. A sample site (an ASP.NET Core MVC application) with three pages is also included in the repository:
- Pages with a straightforward table
- Pages with a "hidden link" and
- A button that only displays after a timeout
Producingnoopener noreferrer"> ASP.NET Core Web API Using Visual Studio 2022
With.NET 6.0, Visual Studio 2022 can be used to develop an ASP.NET Core Web app API. Using Visual Studio, you must give the project a legitimate name and select the ASP.NET Core Web app API template.
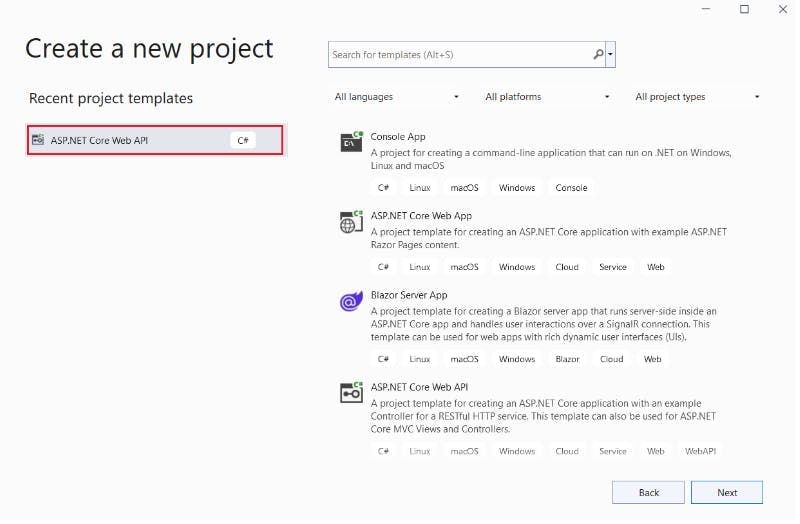
You have the net core web API 6.0 framework as an option. Additionally, you can select the Open API default support. For the project, this will result in sass metadata.
The APIs listed here should be installed leveraging the NuGet package manager.
- HtmlAgilityPack
- Microsoft.EntityFrameworkCore.SqlServer
- Microsoft.EntityFrameworkCore.Tools
For Static Pages
Setup
If you utilize C# chances are good that you already work with Visual Studio. In this post, a specific MVC-based.NET Core web app project is used (Model View Controller).
Leverage the NuGet package manager to incorporate the required libraries used during this whole guide after creating a brand-new project.
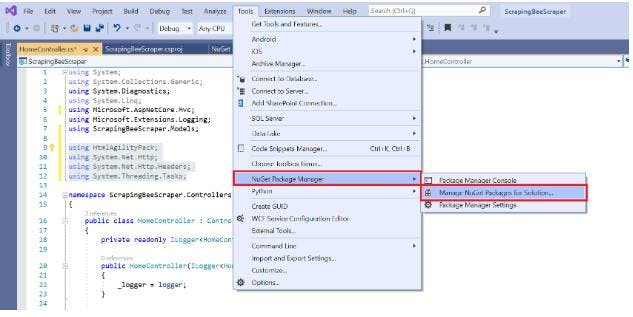
To download the packages in NuGet, select the "Browse" option and then enter "HTML Agility Pack."
You are now prepared to proceed after installing the package. The acquired HTML table may be easily parsed using this package to locate the tags and data you wish to save.
The following APIs must be included in the code before you begin coding the scraper via the visual studio:
Using C# to Send an HTTP Request to a Web Page
Consider a sample project in which you are required to scour Wikipedia for details on well-known computer programmers. If there weren't an article about this, Wikipedia wouldn't be Wikipedia, right?
https://en.wikipedia.org/wiki/list-of-programmers
A list of developers with hyperlinks to each person's Wikipedia page may be found in that article. For later usage, you may scrape the listing and save the data to a CSV format (which, for example, Excel can readily process).
The main idea behind online web scraping is to locate a website that holds the required data, use C# to scrape the information, and save it for later use. This is just one straightforward instance of what you could accomplish with web scraping.
The hyperlinks on a top category page can be used to crawl web pages in more complicated projects. However, let's concentrate on that specific Wikipedia page for the following examples.
Getting HTML with .HttpClient NET Core Web APIs
A built-in HTTP client for.NET is called HttpClient and is available by default. No independent third-party libraries or plugins are required because the Net.HTTP domain does it all. Additionally, it includes native support for delayed calls.
The following example shows how easy it is to obtain any URL's content in an asynchronous, non-blocking manner by using GetStringAsync()
private static async Task<string> CallUrl(string full URL)
{
HttpClient client = new HttpClient();
var response = await client.GetStringAsync(full URL);
return response;
}
You merely generate a brand-new HttpClient object, call GetStringAsync(), "wait" for it to finish, and then give the caller the result. Now that technology has been added to the controller class, you can call CallUrl() from the Index() method without further action. Let's carry that out.
public IActionResult Index(){
string url = "https://en.wikipedia.org/wiki/List_of_programmers";
var response = CallUrl(url).Result;
return View();}
Here, we specify the URL for Wikipedia in the URL, call it with callUrl(), and save the return in the dependent variables.
Okay, the code needed to send the HTTP request has been completed. Although we have still not processed it, it's an excellent idea to run the code immediately to ensure that the Wikipedia HTML is received rather than any mistakes.
To do that, we'll first place a halt at return View() in the Index() method. This will make sure that you're able to see the results using the Visual Studio debugger UI.
By selecting the "Run" option from the Visual Studio toolbar, you may test the code mentioned above: At the breakpoint, Visual Studio will halt, allowing you to see the application's present state.
Levitating over the variable reveals that the server sent back a valid HTML page, indicating that we should be ready to go. If you choose "HTML Visualizer" from the context menu, you will see a preview of the HTML page.
HTML Parsing
It's now time to parse the HTML table that has been retrieved. A well-liked parser suite called HTML Agility Pack can be readily integrated with LINQ, for instance.
You must understand the page's structure before parsing the HTML table so that you can precisely identify which elements to retrieve. The developer tools in your browser will yet again come in handy in this situation because they let you thoroughly examine the DOM tree.
We'll see from our Wikipedia page that the links in our Table of Contents are plentiful, so that we won't need those. There are other additional links as well, some of which we don't absolutely need for our data collection (like the edit links).
When we look deeper, we see that each link that interests us is contained within a li> parent. We now know that li>s are utilized for both the content table on the page and our real link components based on the DOM tree.
Since we don't actually want the content table, you must ensure that those li>s are filtered out. Luckily, they have separate HTML classes, so we can easily omit any li> elements with section classrooms in the code.
Coding time now! We'll begin by including the method ParseHtml in our controller class ().
Here, we initially build a HtmlDocument instance and then upload the HTML page we previously downloaded through CallUrl (). Now that we possess a legitimate DOM representation of our page, we can start scraping it.
- We receive all li> offspring from Descendants ()
- To filter out items that use the aforementioned HTML classes, we leverage LINQ (Where()).
- In our wikiLink string lists, we traverse (for each) across our links and preserve their (relative) URLs as relative URLs.
We give our caller back the string list.
XPath
We wouldn't have been required to choose the elements individually, and it's important to notice. We only did it to set a good example.
Applying an XPath query will be considerably more practical in real-world programs. That would allow our entire selection process to fit into a single sentence.
Similar to our conventional procedure, this will choose any (//) li> that does not have the specified class (not(contains())).
Creating a File for Scraped Data Export
The HTML table text was downloaded from Wikipedia, parsed/processed into a DOM tree, and all the needed links were successfully extracted. As a result, we now possess a general list of hyperlinks from the page.
The links should now be exported to a CSV file format. To write information from the general list to a file, we'll build a new method called WriteToCsv(). The complete procedure is shown in the code that follows.
It creates a file on the local hard disk called "links.csv" and saves the extracted hyperlinks in it. So, write data into a file on a local disk leveraging native.NET framework APIs.
Conclusion
With tools like WebScrapingAPI, it is very simple to construct a crawler project and gather the required information quickly. C# and.NET, in general, contains all the required resources and libraries to enable you to enforce your own data scraper.
The various methods to prevent being blocked or having your rate reduced by the server is one topic we only briefly touched on. Usually, rather than any technical restrictions, it is what stands in the way of web scraping.
If you'd rather concentrate on your data than deal with user agents, rate restrictions, proxies, and JavaScript difficulties take a look at WebScrapingAPI's state-of-the-art features.



