Web Scraping with PHP: The Ultimate Guide To Web Scraping
Sorin-Gabriel Marica on Jan 14 2023
The Internet is a vast place with over 4.7 billion users, and it’s continuously growing. To put it into perspective, over 50% of the earth’s population uses the Internet as of 2018.
Of course, more users mean data as well. Right now, the Internet is so big that it’s estimated that Google, Amazon, Microsoft, and Facebook alone store somewhere around 1.2 million terabytes.
Even a fraction of that information can create new business opportunities. With that in mind, it’s no wonder how popular web scraping has become.
Understanding web scraping
The Internet’s wealth of data is woefully spread thin across billions of websites. As such, developers need a way to collect and process it, to provide users with new innovative products. However, manual information gathering is definitely not a great idea as the volume is often too great, and the data changes continuously.
The solution is automatically extracting it. That’s what web scraping does in a nutshell.
Why you should scrape data
With more information comes more ideas, opportunities, and benefits. Once processed, it can be invaluable to you or your customers. Here are just a few ways web scraping can be used:
- Price comparison tools - Scraping multiple websites to get an overview of how a product type is priced.
- Market research - Learning who are your most important competitors and what they are doing.
- Machine Learning - Collecting training and testing data sets for a machine learning model.
- Any idea that requires access to a considerable amount of data.
For example, a possible use case is building a nutritional app that allows users to add their meals. Ideally, the users will just open the app, search for the products they ate, add them to the tool, and keep track of how many more calories they can eat afterward.
However, the tool needs to provide an extensive list of all possible products and their nutritional values. This list can be created and automatically updated by scraping the nutritional information from multiple websites.
The challenges of web scraping
While web scraping is very handy for whoever is using the bot, sometimes websites aren’t happy to share their content, and they may try to stop you. Some of the ways they may choose to do so are:
- Captcha Codes - Any page can use Captchas, even if it doesn’t show. When you make multiple requests, a captcha code may show up and break your web scraper.
- IP Blocking - Some websites choose to block your IP once they see excessive traffic coming from your side.
- Geo-Blocking - Some content may be available just in specific countries, or you might receive data particular to a region when you want information on another.
- Javascript - Most of today’s websites use javascript in one way or another. Some may display their content dynamically, complicating matters since the page source is not the same as the rendered page content.
Overcoming these challenges can require a lot of work, but there are options. To help you, we created WebscrapingAPI, which takes care of all these problems while helping you build your solution faster and with fewer headaches.
Understanding the web
Whenever an Internet user accesses a website, the browser will create an HTTP (Hypertext Transfer Protocol) request. You can think of a request as a message from the client (the user’s computer) to the server (the computer where the website is located) where the client specifies what he wants to receive.
For each request sent, you’ll get a response. The response can be successful, or an error, such as the famous ‘404 page not found error code. The content of a website is usually found in the body of the response received from the server.
Both the requests and the response contain a head, and a body used to exchange information. Also, the requests can be of multiple methods, the most common being GET (this is used when accessing a web page). These methods indicate the action the client wants to do.
For example, when registering or updating your password on a website, you want your data to be hidden in the browser, and websites can use the method POST or PUT for this type of request.
The head of a request contains multiple properties. Let’s go over the most important ones:
- Host - The domain name of the server.
- User-Agent - Details about the client that made the request, such as browser and operating system.
- Cookie - A set of properties associated with the client.
- Accept - A parameter used to receive the response for the server in a specific type such as text/plain or application/json.
Requests are exclusive to web pages, though. They are made for images, styles, and javascript code as well, separately from the page. You can get a glance at all the requests your Google Chrome browser makes when accessing a web page by pressing F12 on a page, choosing the tab “Network” and refreshing the page you are on. You should see at the end something like this:
Understanding PHP
PHP is one of the oldest and most popular web programming languages used for application backends. It’s been around since 1995, and now it’s on its 8th version.
Programmers choose this programming language because of its simple syntax and easy way to run, as all you need to run PHP code is a machine with PHP installed. Furthermore, since it’s been around for so long, there are many resources and support for solving and debugging PHP errors.
PHP also has many popular frameworks and CMSs (Content Management System) built on this programming language. Famous examples are WordPress, Drupal, Magento, and Laravel.
Still, there are some disadvantages as well. For example, it’s more difficult to scrape dynamic content compared to Python or Javascript. However, if you only need information from simple pages, PHP is definitely a good solution, and it can help you save or store the scraped data much easier.
What you will need
All good so far? Ready to create your first web scraper? Before starting, you should have a way to run your PHP code. You can choose an Apache/Nginx server with PHP installed and run the code directly from your browser, or you can run the code from your command line.
Let’s make our lives easier by using a library to process the scraped content. Some of the popular PHP scraping libraries are Goutte, Simple HTML DOM, Panther, and htmlSQL. Alternatively, you may choose to process the content using regular expressions.
For this guide, we will use Simple HTML DOM. However, for more advanced requests, we will also use the PHP library called CURL.
Using Simple HTML Dom
Simple HTML Dom it’s a library developed for PHP versions from 5.6 upwards, and it allows us to access the page’s content in a much easier way — with selectors. You can download the library from here, and you should also read the documentation.
From the zip file in the download link, you will only need the simple_html_dom.php file, which you should put in the same folder where you’ll write the code for the scraper.
To include the library in the code, you only need this one line of code:
include 'simple_html_dom.php'; // If the library is in another folder you should do include 'path_to_library/simple_html_dom.php'
Installing PHP-CURL
While it’s not always necessary, you’ll need to send different headers for more advanced requests. Using the PHP-CURL library will help.
To install it on a Ubuntu machine, you can use the following command:
sudo apt-get install php-curl
After installing the library, don’t forget to restart your Apache/Nginx server.
Making your own web scraper
Now that we have all that we need, it’s time to extract data! First, you should decide on the website and the content you want to scrape. For this article, we will scrape the contents from IMDB’s Top Rated Movies List.
1. Inspect the website’s content
Most web content is displayed using HTML. Since we need to extract specific content from the HTML source, understanding it is required as well. We need first to inspect what the page source looks like to know what elements to extract from the page.
You can do this in Google Chrome with a right-click on the element you want to extract and then choosing “Inspect Element”. This should open a window in your browser with the page source and the rendered styles of the elements. From this window, the only tab that we need to check is “Elements”, which will show us how the page’s HTML dom is structured.
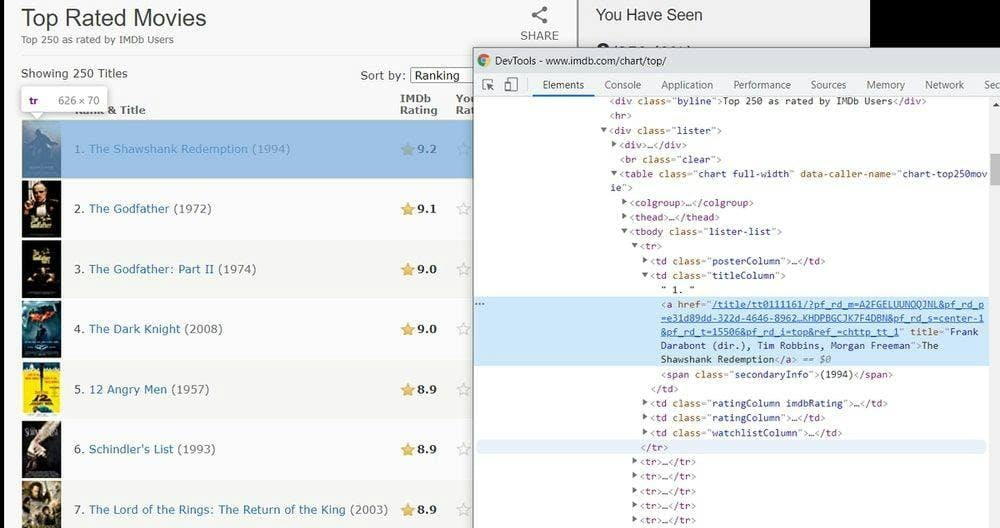
For example, the page contains a table with the class “chart” and “full-width” in the image above. In this table, each cell has its own class (posterColumn, titleColumn, and so on), which we can use to create a selector. Then, we can access only the needed data.
Confused? Don’t worry, the following steps will clarify things.
2. Send a request from PHP
Sending a request, in this case, basically means accessing the HTML of a page directly with PHP code. There are two ways to do that.
First, we can use the PHP-CURL library, which also allows us to modify the headers and the body we send in our request.
<?php
header("Content-Type: text/plain"); // We choose to display the content as plain text
$ch = curl_init("https://www.imdb.com/chart/top/");
curl_setopt($ch, CURLOPT_HEADER, 0);
$response = curl_exec($ch); // Running the request
if (curl_error($ch)) {
echo curl_error($ch); // Displaying possible errors from the request
} else {
echo $response; // Displaying the content of the response
}
curl_close($ch);
?>
Another option is a one-liner, using the file_get_contents($url) method, but this can be insufficient for some instances. To send headers to this request, you need to use a context created with the stream_context_create method.
<?php
header("Content-Type: text/plain"); // We choose to display the content as plain text
echo file_get_contents('https://www.imdb.com/chart/top/'); // We retrieve and display the contents of the response in a single line
?>
You should decide on what method to use based on the complexity of the scraper that you want to build.
The two pieces of code from above will display the HTML source of the page that we are scraping, the same one that is visible when you inspect the website. We’ll use the first line of the code to display the results as a text/plain. Otherwise, it will be rendered directly as html.
If there are any differences in the HTML structure, then a javascript code is running on the website and changing the content once a user accesses it. We’ve prepared a tip on how to deal with that later in the article.
3. Extract the data
From our chosen page, we will extract only the title of the movies and the rating associated with each of them. As we saw earlier, the content is displayed in a table where each cell has its class.
Using this, we can choose to extract all the rows of the table. Then we look through each individual row for the cells that interest us.
The following piece of code should do just that:
<?php
header("Content-Type: text/plain"); // We choose to display the content as plain text
include 'simple_html_dom.php';
$html_dom = file_get_html('https://www.imdb.com/chart/top/'); // We retrieve the contents using file_get_html from simple_html_dom
$table_rows = $html_dom->find('table.chart tbody tr'); // Getting all of the table rows
foreach($table_rows as $table_row) {
$title_element = $table_row->find('.titleColumn a', 0);
$rating_element = $table_row->find('.ratingColumn strong', 0);
if (!is_null($title_element) && !is_null($rating_element)) { // Checking if the row has a title and a rating column
echo $title_element->innertext . ' has rating ' . $rating_element->innertext . PHP_EOL; // If it does then we print it
}
}
?>
You can notice that we used the selector “table.chart tbody tr” to extract all of the rows of the table. It’s good to use selectors that are as specific as possible so that you can differentiate the elements you need from the rest.
After retrieving the rows, we looped through them, looking for elements with the class titleColumn or ratingColumn. If the code found any, it displayed their innerText property.
It’s important to note that we used file_get_html instead of file_get_contents for this example. That’s because this function comes from the simple_html_dom library, and it works as a wrapper for the file_get_contents function.
4. Export the data
In the above examples, we collected the site data and displayed it directly on the screen. However, you can also save the data in PHP quite easily.
You can save the scraped data in a .txt file, as a JSON, as a CSV, or even send it directly to a database. PHP it’s very good at that. We just have to store it in an array and put the array’s contents in a new file.
<?php
include 'simple_html_dom.php';
$scraped_data = [];
$html_dom = file_get_html('https://www.imdb.com/chart/top/'); // We retrieve the contents using file_get_html from simple_html_dom
$table_rows = $html_dom->find('table.chart tbody tr'); // Getting all of the table rows
foreach($table_rows as $table_row) {
$title_element = $table_row->find('.titleColumn a', 0);
$rating_element = $table_row->find('.ratingColumn strong', 0);
if (!is_null($title_element) && !is_null($rating_element)) { // Checking if the row has a title and a rating column
$scraped_data[] = [
'title' => $title_element->innertext,
'rating' => $rating_element->innertext,
];
}
}
file_put_contents('file.json', json_encode($scraped_data)); // Saving the scraped data in a .json file
// Saving the scraped data as a csv
$csv_file = fopen('file.csv', 'w');
fputcsv($csv_file, array_keys($scraped_data[0]));
foreach ($scraped_data as $row) {
fputcsv($csv_file, array_values($row));
}
fclose($csv_file);
?>
The code from above takes the same content that we extracted earlier and creates two files, a csv, and a json, with all of the top-rated movies and their ratings.
Tips and Tricks
1. Error Handling
When coding in PHP and scraping data from websites that might change at any time, it’s normal for errors to appear. A good piece of code that you can use for debugging is the following three lines, placed at the beginning of any PHP script:
ini_set('display_errors', '1');
ini_set('display_startup_errors', '1');
error_reporting(E_ALL);These will help you identify problems in your code faster and update your script when necessary.
2. Setting headers in requests for PHP
Sometimes when making a request, you may need to send some headers as well. For example, when working with an API, an authorization token might be necessary, or you may want the content to come as a JSON instead of plain text. You can add headers both with curl and file_get_contents. Here is how to do it with curl:
$ch = curl_init("http://httpbin.org/ip");
curl_setopt($ch, CURLOPT_HEADER, [
'accept: application/json'
]);
$response = curl_exec($ch); // Running the requestAnd for file_get_contents:
$opts = [
"http" => [
"method" => "GET",
"header" => "accept: application/json\r\n"
]
];
$context = stream_context_create($opts);
$result = file_get_contents("http://httpbin.org/ip", false, $context);
3. Using curl or file_get_contents with simple_html_dom
When we extracted content from IMDB, we used the function file_get_html from simple_html_dom to scrape. This approach works for simple requests but not necessarily for the more complicated ones. If you need to send headers, you’d better use one of the methods used in the previous tip.
To use them instead of file_get_html, just extract the content and then use str_get_html to convert it into a dom object, like this:
$opts = [
"http" => [
"method" => "GET",
"header" => "accept: text/html\r\n"
]
];
$context = stream_context_create($opts);
$result = file_get_contents("https://www.imdb.com/chart/top/", false, $context);
$html_dom = str_get_html($result);
Also, keep in mind that simple_html_dom has by default some limits (which can be found in the simple_html_dom.php file). For example, the content of the website can have up to 600,000 characters. If you want to change this limit, you just need to define it at the top of your code before including the simple_html_dom library:
define('MAX_FILE_SIZE', 999999999);4. Scraping dynamic content
If you’re scraping a dynamic website, you’ll need to access it as a browser would. Otherwise, you won’t be able to extract actual data and will get js code instead.
You will need to install a browser driver, such as chromium-chromedriver or firefox-geckodriver. Extracting the dynamic content in PHP is a more advanced lesson, but if you’re interested, you can try to do it by reading the documentation of the panther library.
Alternatively, a much simpler solution is to use WebScrapingAPI, which makes most problems go away. The API overcomes IP blocks and Captchas by using our proxy network while also rendering javascript. The result: you have an advanced scraper immediately, cutting down on development and wait time.
Here is a code sample that will display the content from https://httpbin.org/ip directly in PHP, through our API:
$content =
file_get_contents("https://api.webscrapingapi.com/v1?pi_key=YOUR_API_KEY&url=". urlencode('https://httpbin.org/ip'));
echo $content;
Conclusion
Congratulations on reaching the end! You should now have all you need to build your Web Scraper with PHP. While we only explored the simple_html_dom library in this article, you can try other popular libraries and see for yourself which one suits you better.
Remember that websites are constantly changing, and their data might update overnight. To help with this, you can use more specific selectors. Of course, it’s no guarantee that your scraper will work forever, but it’s a start. That’s why web scrapers require continuous, time-consuming updates.
If you don’t feel like you want to spend all that time researching and adapting your code, you can always try the WebScrapingAPI free trial!
News and updates
Stay up-to-date with the latest web scraping guides and news by subscribing to our newsletter.
We care about the protection of your data. Read our Privacy Policy.

Related articles

Explore the complexities of scraping Amazon product data with our in-depth guide. From best practices and tools like Amazon Scraper API to legal considerations, learn how to navigate challenges, bypass CAPTCHAs, and efficiently extract valuable insights.


Explore the transformative power of web scraping in the finance sector. From product data to sentiment analysis, this guide offers insights into the various types of web data available for investment decisions.


Dive into the transformative role of financial data in business decision-making. Understand traditional financial data and the emerging significance of alternative data.